近日,我中心多篇论文被国际权威会议录用,包括:ICML 2026 3篇(含合作1篇)、IJCAI-ECAI 2026 3篇、ACL 2026 13篇(含合作5篇),CVPR 1 篇,ICDE 1 篇。
ICML 2026会议全称为The Forty-Third International Conference on Machine Learning,在CCF学术推荐列表中被认定为A类会议,并将于2026年7月6日至11日在韩国首尔举行。
IJCAI-ECAI 2026会议全称为The 35th International Joint Conference on Artificial Intelligence,在CCF学术推荐列表中被认定为B类会议,并将于2026年8月15日至21日在德国不来梅举行。
ACL 2026会议全称为The 64th Annual Meeting of the Association for Computational Linguistics,在CCF学术推荐列表中被认定为A类会议,并将于2026年7月2日至7日在美国圣地亚哥举行。
CVPR 2026会议全称为The 43rd IEEE/CVF Conference on Computer Vision and Pattern Recognition,在CCF学术推荐列表中被认定为A类会议,并将于2026年6月3日至7日在美国科罗拉多州丹佛市的科罗拉多会议中心举行。
ICDE 2026会议全称为The 42nd IEEE International Conference on Data Engineering,在CCF学术推荐列表中被认定为A类会议,并将于2026年5月4日至8日在加拿大蒙特利尔举行。
此次被录用的论文的相关信息如下:
论文题目:1、ANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference in Large Language Models
录用类型:ICML 2026, Main Track
论文作者:Wentao Qiu, Guanran Luo, Zhongquan Jian, Jingqi Gao, Meihong Wang, Qingqiang Wu*
完成单位:厦门大学
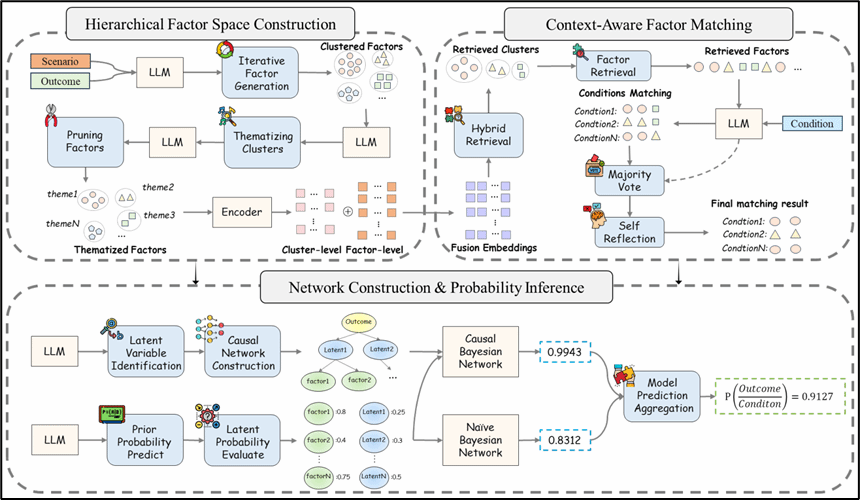
论文简介:面向大语言模型在复杂决策场景中的可信概率推理问题,现有溯因-贝叶斯方法存在结构性短板:因子空间稀疏且缺乏层次组织,导致条件映射困难、未知预测比例高;盲目扩展因子又会引入噪声与伪相关,破坏朴素贝叶斯条件独立性假设,影响推理稳定性。因此,在保持因子表达力的同时实现可靠概率估计成为核心挑战。针对上述痛点,本文提出ANCHOR框架,构建分层溯因网络建模方法。其核心创新有三:一是通过自底向上的迭代溯因机制,系统扩展并组织高质量因子,形成稠密可解释的层次化因子空间;二是引入上下文感知的层次检索、自一致性筛选与反思式修正,实现高置信度的条件-因子映射;三是在朴素贝叶斯基础上构建潜变量增强的因果贝叶斯网络,显式建模因子间潜在依赖,并通过多模型概率融合提升稳健性。实验表明,ANCHOR在偏好评估、推理规划与事实核查等任务中均优于基线,显著降低未知预测比例,提升概率估计与人类判断的一致性,同时减少推理时间、token消耗与API调用成本。
论文题目:2、ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models
录用类型:ICML 2026, Main Track
论文作者:Yujie Lin+, Chengyi Yang+, Zhishang Xiang, Yiping Song, Jinsong Su*
完成单位:厦门大学,国防科技大学
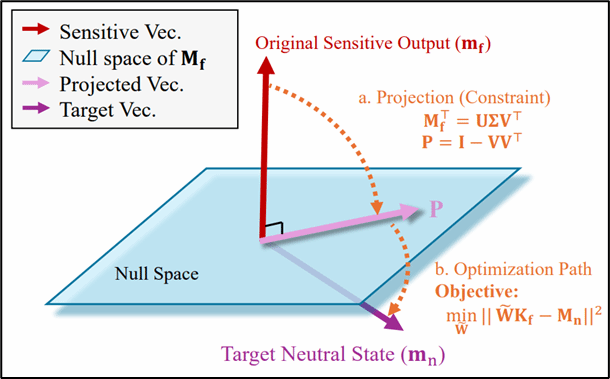
论文简介:随着大语言模型在搜索、对话、内容生成等场景的深度普及,模型训练中不可避免记忆大量敏感数据、隐私信息与过时知识,引发数据合规、隐私泄露及内容安全风险。机器遗忘作为解决该问题的关键技术,旨在让模型定向忘掉指定知识。现有遗忘方法存在明显短板:全量重训练计算成本极高,超大规模模型难以工程落地;激进微调易引发“连带遗忘”,删除目标知识的同时破坏语义相关良性知识,导致模型语言能力、生成质量及通用任务性能大幅下降。因此,小样本条件下实现精准、高效、无损的知识擦除,成为大模型安全领域的核心挑战。针对上述痛点,我们创新将机器遗忘转化为基于模型编辑的精准知识重映射问题,提出小样本知识遗忘框架ZeroUnlearn。其核心是不破坏性扰动模型权重,将敏感输入映射到中性目标状态,并通过乘法参数更新强制编辑后表征与原始敏感表征正交化,从特征空间彻底消除敏感知识影响。
论文题目:3、PointGP: Geometry-Primed Attention for Point Cloud Analysis
录用类型:IJCAI-ECAI 2026, Main Track
论文作者:Yong Yang, Jianming Huang, Mengyuan Ge, Chunyang Huang, Bingbing Hu, JunfengYao*
完成单位:厦门大学
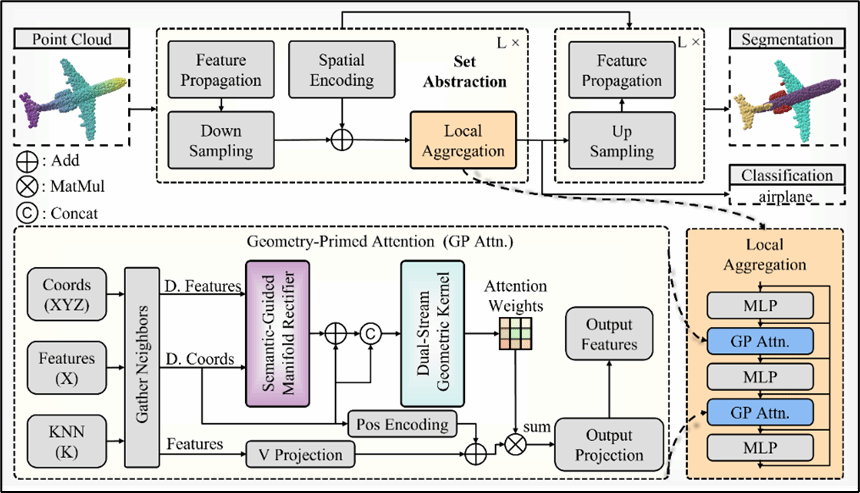
论文简介:该论文针对现有基于Transformer的三维点云理解方法中存在的局限性展开研究。当前主流方法通常遵循“以特征为中心”的范式,其注意力权重完全由语义相似性驱动。本研究发现,在深层网络中,这种设计容易引发特征同质化(亦称秩坍塌)问题,进而削弱注意力机制的结构选择性。为解决这一挑战,我们提出了PointGP框架,创新性地引入几何引导的建模视角。与仅将几何信息作为辅助编码的现有方法不同,PointGP将几何拓扑作为稳定的结构锚点来生成注意力。具体而言,框架包含两个核心模块:语义引导的流形矫正器,能依据语义线索自适应调整度量空间;以及双流几何核,直接从矫正后的几何拓扑中显式推导注意力权重。该设计在解耦显式特征匹配与注意力生成的同时,通过几何感知的矫正隐式引导特征聚合。在点云分类、部件分割与场景分割等多个标准数据集上的实验表明,PointGP在取得具有竞争力性能的同时,保持了较高的参数效率,优于当前主流方法。
论文题目:4、Efficient and Exact Global Attention on Latent Summaries for Knowledge Graph Reasoning
录用类型:IJCAI-ECAI 2026, Main Track
论文作者:Chenxiao Lin, Lei Wang, Yin Zhang, Wei Liu, Ye Luo, Qingqiang Wu*
完成单位:厦门大学
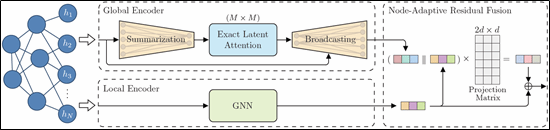
论文简介:面向知识图谱中的消息传播问题,路径缺失与长路径衰减严重限制了多跳推理能力。全局注意力机制作为突破路径屏障的关键技术,旨在通过线性注意力计算全局节点关联。此前工作虽采用线性注意力,但输出分布平滑化且在归纳式推理中因实体数量变化引发严重注意力熵偏移,缺乏理论保障与结构约束。因此,在保持高效率的同时实现稳定、可泛化的全局消息传播,成为知识图谱推理的核心挑战。针对上述痛点,本文创新提出基于潜在摘要空间的注意力框架,将全局节点映射到固定潜在摘要空间后执行原始Softmax计算,从根本上避免熵偏移。其核心包括:自适应全局与本地特征融合策略,兼顾实体结构异质性;基于JL引理与切诺夫界严格证明熵偏移现象及潜在摘要空间大小上下界;通过Welch界分析向量分布并引入正交正则化惩罚,缓解输出平滑化。实验表明,该框架在12个归纳式与4个直推式数据集上均显著提升,消融与分布对比实验验证了理论正确性。
论文题目:5、Towards Fine-Grained Code-Switch Speech Translation with Semantic Space Alignment
录用类型:IJCAI-ECAI 2026, Main Track
论文作者:Yan Gao, Yazheng Yang*, Zhibin Lan, Yidong Chen, Min Zhang, Daimeng Wei, Derek F. Wong, Jinsong Su*
完成单位:厦门大学,华为,澳门大学
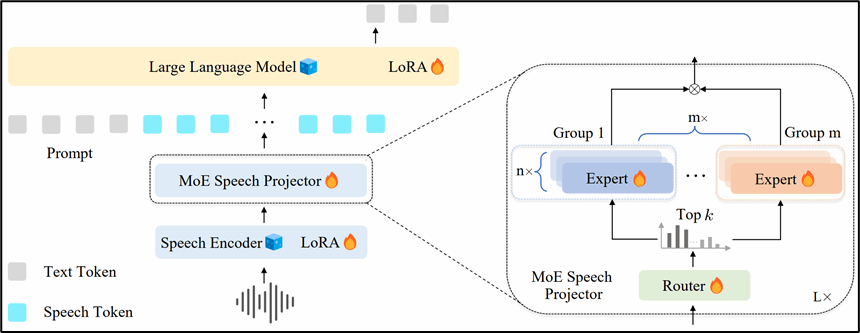
论文简介:该论文针对语码转换语音翻译任务中语义建模复杂性与数据稀缺两大挑战展开研究。现有方法通常依赖模型自身去隐式学习跨语言语义,并使用成本高昂的标注数据或质量欠佳的合成数据,限制了模型在语码转换场景下的能力。本研究发现,不同语言的语音特征在语义空间中存在显著差异,且共享投影器难以有效捕捉跨语言语义差异。为解决这一问题,我们提出了一套结合模型架构与训练策略的解决方案。具体而言,在架构层面我们设计了混合专家投影器,将专家按语言分组,使各组专注于特定语言的语义空间,实现对语音特征的细粒度建模。在训练层面则引入多阶段训练范式,充分利用易获取的单语语音识别与翻译数据来强化语义对齐与翻译能力,提出迁移学习损失逐步适配到语码转换语音翻译场景,并提出语言特定损失与组内负载均衡损失确保专家组间的专业化与专家组内的负载均衡。
论文题目:6、AGSC: Adaptive Granularity and Semantic Clustering for Uncertainty Quantification in Long-text Generation
录用类型:ACL 2026, Main, Long paper
论文作者:Guanran Luo, Wentao Qiu, Wanru Zhao, Wenhan Lv, Zhongquan Jian, Meihong Wang, Qingqiang Wu*
完成单位:厦门大学
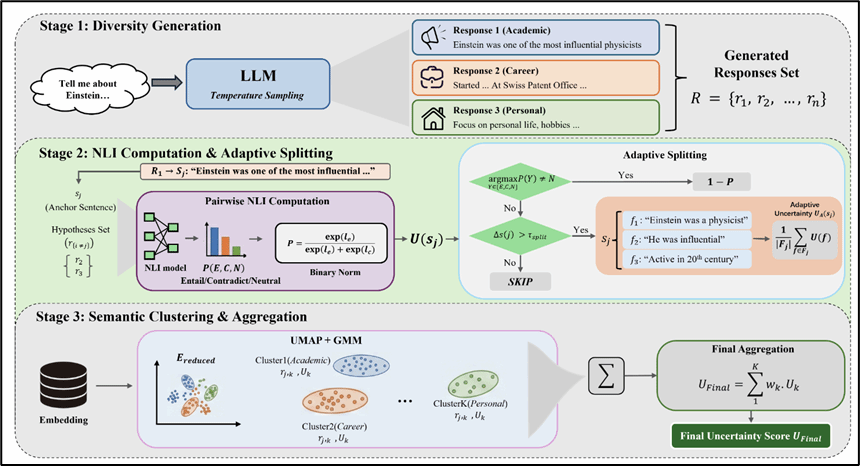
论文简介:面向大语言模型长文本生成中的可信性评估问题,现有不确定性量化方法在细粒度事实分解、跨主题聚合和计算效率方面存在不足。长文本常含多主题、多粒度事实单元,整体置信度判断难以捕捉局部幻觉,而原子事实级分解又导致高昂推理开销。因此,在兼顾精细度与效率的前提下实现可靠的事实性评估成为核心挑战。针对上述痛点,本文提出AGSC框架,引入自适应粒度分析与语义聚类相结合的不确定性建模机制。其核心创新有二:一是利用自然语言推理中的neutral信号区分“无关信息”与“潜在不确定内容”,动态决定是否进一步分解为原子事实,避免不必要的细粒度拆解;二是通过基于高斯混合模型的软语义聚类建模长文本中的潜在主题结构,为不同主题分配自适应权重,实现稳健的全局不确定性聚合。实验表明,AGSC在BIO、LongFact等长文本事实性评估数据集上取得了优于现有方法的相关性表现,同时显著降低了计算成本,为长文本生成可靠性评估提供了更高效、更精细的技术路径。
论文标题:7、LegalGraphRAG: Multi-Agent Graph Retrieval-Augmented Generation for Reliable Legal Reasoning
录用类型:ACL 2026, Main, Long paper
论文作者:Zerui Chen, Qinggang Zhang*, Zhishang Xiang, Zhimin Wei, Linfeng Gao, Xiao Huang, Zhihong Zhang*, Jinsong Su*
完成单位:厦门大学,香港理工大学
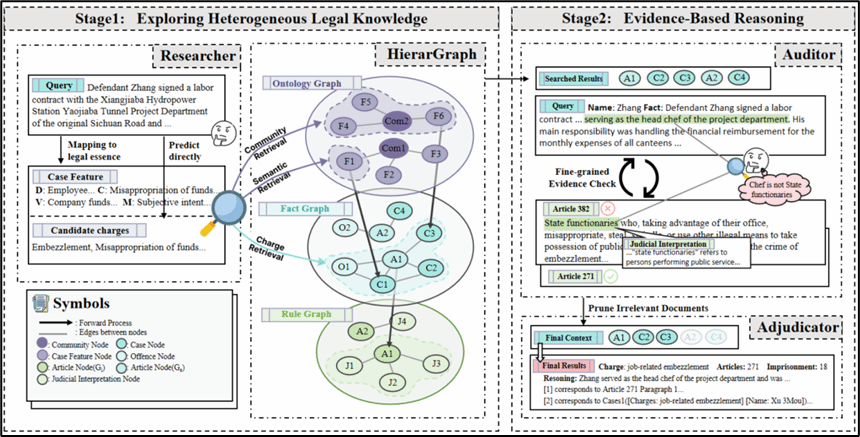
论文简介:基于图的检索增强生成(GraphRAG)在处理专业领域任务中展现出巨大潜力,然而,将其应用于法律推理等严谨的垂直领域时却面临着重大挑战。现有的扁平图结构无法有效处理包含案例、法条和司法解释的异构多粒度法律知识,限制了检索的准确性;同时,传统的RAG系统往往在未经验证的情况下直接将上下文传递给大语言模型,导致“检索-生成”的推理过程不透明且易产生错误。针对这些痛点,本研究提出了创新性的LegalGraphRAG框架。该框架引入了多层级法律图谱,实现了对多粒度法律信息的高效组织与精准检索;此外,系统设计了一个多智能体工作流,通过检索候选证据、严格验证其有效性并对核实的证据进行综合分析,将法律判决转化为透明的证据驱动流水线。大量的实验结果表明,该方法不仅超越了现有的GraphRAG基准和专业法律大模型,还能确保每一项结论都具备清晰的法律证据支撑,显著提高了生成结果的准确性与可信度。
论文标题:8、HEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment
录用类型:ACL 2026, Main, Long paper
论文作者:Zhanyu Liu+, Qingguo Hu+, Ante Wang, Chenqing Liu, Zhishang Xiang, Hui Li, Delai Qiu, Jinsong Su*
完成单位:厦门大学,厦门云知芯,清华大学
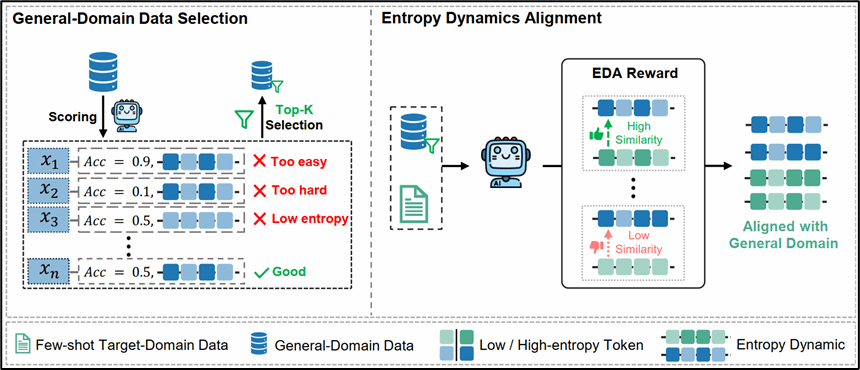
论文简介:基于可验证奖励的强化学习(RLVR)在训练推理导向的大语言模型方面已展现出显著成效,但现有方法大多假设资源充足、训练数据丰富。在低资源场景下,RLVR 极易遭遇更为严重的熵坍缩问题,这极大地限制了探索空间,并削弱了推理性能。为此,我们提出混合域熵动态对齐(HEAL)框架,专为少样本 RLVR 设计。HEAL 首先有选择地融入高价值通用域数据,以促进更多样化的探索。随后,我们引入熵动态对齐(EDA)奖励机制,该机制能够对齐目标域与通用域之间的轨迹级熵动态,不仅捕捉熵的大小,还刻画其精细变化。通过这种对齐,EDA 不仅进一步缓解了熵坍缩,还鼓励策略从通用域习得更丰富的探索行为。跨多个领域的实验结果表明,HEAL 能够持续提升少样本 RLVR 的性能。值得注意的是,仅使用 32 条目标域样本,HEAL 即可达到甚至超越使用 1000 条目标域样本训练的全量 RLVR 模型水平。
论文题目:9、GCoT-Decoding: Unlocking Deep Reasoning Paths for Universal Question Answering
录用类型:ACL 2026, Findings, Long paper
论文作者:Guanran Luo, Wentao Qiu, Zhongquan Jian, Meihong Wang, Qingqiang Wu*
完成单位:厦门大学
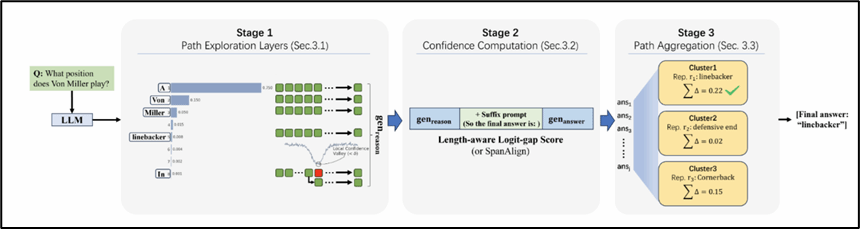
论文简介:面向大语言模型通用问答场景中的深层推理路径挖掘问题,现有CoT-decoding方法因依赖固定答案空间,在开放式问答中泛化能力受限。无提示多路径解码作为提升模型推理能力的有效手段,旨在不依赖人工标注的情况下激发模型自主生成推理路径。传统方法虽能自动生成推理链,但其置信度计算与答案聚合严重依赖可精确匹配的答案片段,难以适应自由形式表达及语义等价答案。因此,摆脱固定答案空间约束、实现鲁棒的路径探索与聚合成为提升问答通用性的核心挑战。针对上述痛点,本文创新提出GCoT-Decoding框架,构建面向通用问答的无提示多路径解码方法。其核心包括:采用Fibonacci采样实现全局路径探索,结合局部置信度低谷回溯修复错误轨迹;将推理与答案生成解耦,设计长度感知的logit-gap置信度评分;引入贪心语义聚类对近义答案进行聚合投票,替代精确匹配。实验表明,GCoT-Decoding在固定答案任务上保持竞争力,在开放式问答中显著提升,展现出更强的任务通用性与鲁棒性。
论文标题:10、HCRE: LLM-based Hierarchical Classification for Cross-Document Relation Extraction with a Prediction-then-Verification Strategy
录用类型:ACL 2026, Findings, Long paper
论文作者:Guoqi Ma+, Liang Zhang+, Hongyao Tu, Hao Fu, Hui Li, Yujie Lin, Longyue Wang, Weihua Luo, Jinsong Su*
完成单位:厦门大学,理想汽车,阿里国际
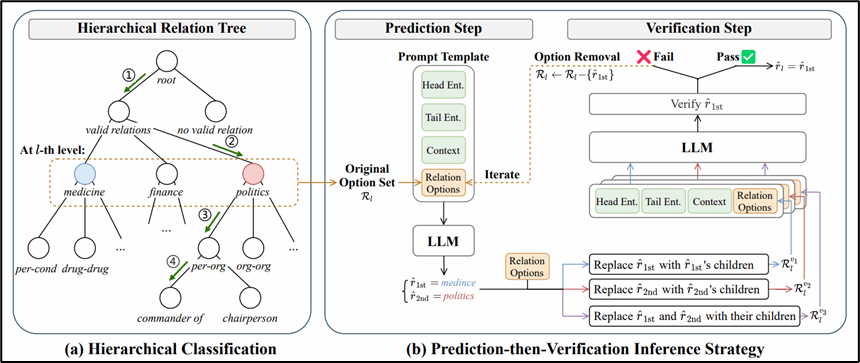
论文简介:现有的跨文档关系抽取研究主要基于“小语言模型+分类头”的范式,要求模型在一次推断过程中从大量语义相似的候选关系中选择出目标关系。然而,这一范式对于语义建模能力有限的小语言模型构成了巨大的挑战。为此,本文提出基于大语言模型层级式分类方法。具体而言,本方法首先根据预定义关系的语义信息进行递归地划分和抽象,构建由高层概念节点到细粒度关系节点逐级展开的层次关系树;随后,在树结构的引导下,大语言模型进行逐层地、自上而下的层级式分类,每次预测从少量的树节点进行选择,从而显著降低单步分类难度。更进一步地,为了缓解层级式分类过程中的错误传播问题,本文设计一种预测验证策略,在每一层级引入细粒度节点信息对当前预测进行一致性检验,提升模型预测的可靠性。该方法首次系统性地将大语言模型适配至跨文档关系抽取任务,实验结果也表明本方法在封闭和开放设置中均取得了最优性能,验证了有效性。
论文标题:11、Orchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR
录用类型:ACL 2026, Findings, Long paper
论文作者:Zijun Min+, Bingshuai Liu+, Ante Wang, Long Zhang, Anxiang Zeng, Haibo Zhang*, Jinsong Su*
完成单位:厦门大学,虾皮,清华大学
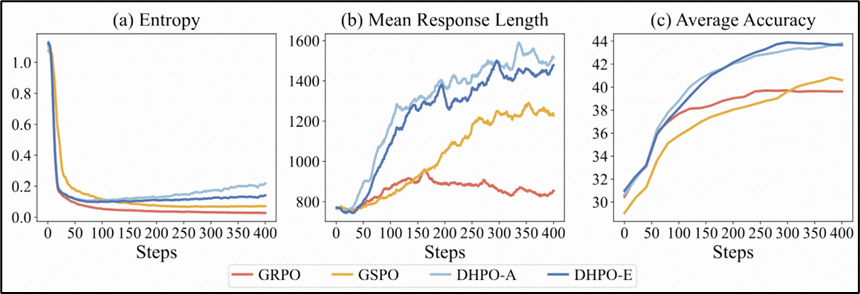
论文简介:可验证奖励强化学习(RLVR)为优化大语言模型的推理能力提供了一个极具潜力的框架。然而,现有 RLVR 算法所关注的优化粒度各不相同,且各自的优势与局限互为补充。组相对策略优化(GRPO)利用词元级重要性比率更新策略,保留了细粒度的功劳分配,但往往面临方差高、训练不稳定的问题。相比之下,组序列策略优化(GSPO)对生成回复中的所有词元统一应用单一的序列级重要性比率,虽能更好地对齐序列级奖励,却牺牲了词元级的信用分配能力。为此,本文提出动态混合策略优化(Dynamic Hybrid Policy Optimization, DHPO),旨通过单一的裁剪函数桥接 GRPO 与 GSPO。DHPO 通过加权机制将词元级与序列级的重要性比率相融合。我们深入探讨了两种混合机制变体:平均混合与熵引导混合。为进一步提升训练稳定性,我们引入了分支特异性裁剪策略,在混合前分别将词元级与序列级比率约束在各自独立的信任域内,从而有效避免任一分支的异常值主导参数更新。在七项高难度数学推理基准测试中,DHPO 的性能始终稳定优于 GRPO 与 GSPO。
论文标题:12、Beyond Black-Box Interventions: Latent Probing for Faithful Retrieval-Augmented Generation
录用类型:ACL 2026, Findings, Long paper
论文作者:Linfeng Gao, Qinggang Zhang*, Baolong Bi, Bo Zeng, Zheng Yuan, Zerui Chen, Zhimin Wei, Shenghua Liu, Linlong Xu, Longyue Wang, Weihua Luo, Jinsong Su*
完成单位:厦门大学,阿里云
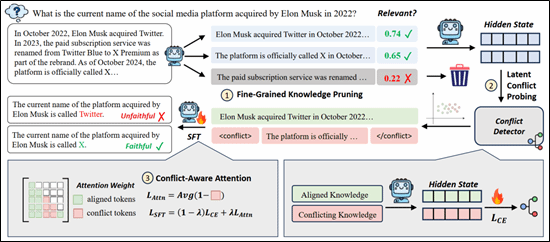
论文简介:检索增强生成(RAG)系统常常难以保持对上下文的忠实性,生成的回答可能与提供的上下文相冲突。现有方法尝试通过外部干预来提升忠实性,例如使用特殊提示、基于解码的校准或偏好优化。然而,由于这些方法将大语言模型视为黑箱,它们缺乏可靠的机制来评估冲突是如何发生的。因此,这些方法往往脆弱、依赖大量数据,并且无法洞察模型的内部推理过程。在本文中,我们超越黑箱式干预,转向分析模型的内部推理机制。我们发现,在模型的潜在空间中,冲突知识状态与一致知识状态是线性可分的,而上下文噪声会系统性地增加这些表示的熵。基于这些发现,我们提出了 ProbeRAG,这一全新的忠实 RAG 框架包含三个阶段:(i)细粒度的知识剪枝,用于过滤无关上下文;(ii)潜在冲突探测,用于识别模型潜在空间中的硬冲突;(iii)基于冲突的注意力机制,用于调整注意力头,使其更好地整合忠实的上下文。实验表明,ProbeRAG 在准确性和上下文忠实性方面都取得了显著提升。
论文标题:13、BAPO: Boundary-Aware Policy Optimization for Reliable Agentic Search
录用类型:ACL 2026, Findings, Long paper
论文作者:Shiyu Liu+, Yongjing Yin+, Jianhao Yan, Yunbo Tang, Qinggang Zhang*, Bei Li, Xin Chen, Jingang Wang, Xunliang Cai, Jinsong Su*
完成单位:厦门大学,美团,香港理工大学
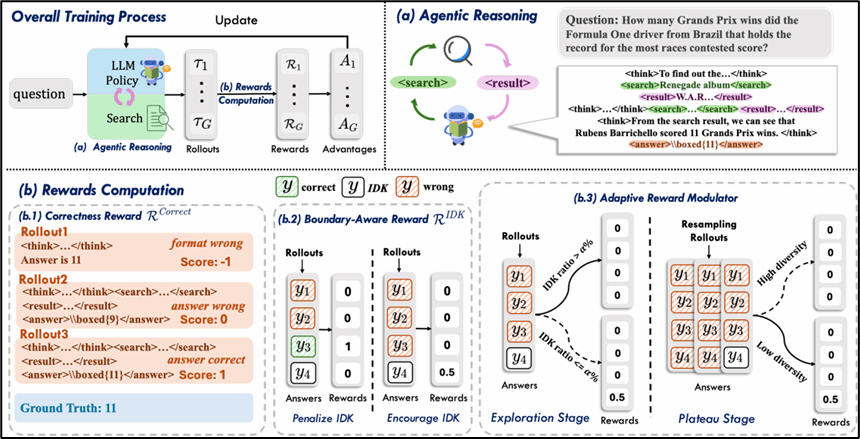
论文简介:尽管当前基于 RL 训练的深度搜索Agent通过在推理中自主搜索显著提升多跳 QA 的性能,但我们的先导实验揭示了一个被忽视的严重问题:基于正确性奖励的RL削弱了模型的推理边界意识。这些 Agent 在搜索不到有效信息时,往往缺乏承认“I Don’t Know” (IDK) 的能力,反而倾向于根据上下文强行编造答案。为此,我们提出了一套系统性的 RL 框架 BAPO,旨在训练更可信的搜索 Agent:1. 边界感知奖励: 基于 GRPO 的组优势算法,我们引入了针对性的奖励机制。对于不存在正确答案的样本组,奖励 IDK 回复,反之则惩罚。这迫使模型习得精准的边界意识,学会拒绝回答超出能力范围或检索信息不足的问题。2. 动态奖励调和器: 仅仅鼓励 IDK 可能会导致模型“变懒”,丧失解决难题的探索欲。我们设计了一个动态调和机制,在早期探索阶段抑制 IDK 奖励,优先鼓励探索;随着训练进行,逐步强化边界约束,有效平衡了“解题能力”与“边界意识”。在 HotpotQA、Musique 等多跳问答数据集上的实验表明,仅用5k的训练样本,BAPO有效提升了 Agent 回答精准率和整体可靠性指标,在培养模型边界意识的同时,仍能保持与 GRPO 相近的准确率。
论文题目:14、Hierarchical Enhancement of Semantic Priors for Disentangled Text-Driven Motion Generation
录用类型:CVPR 2026, Main
论文作者:Wenhan Lv, Shaopan Wang, Xiangyu Wu, Tianchu Hang, Zhongquan Jian*, Qingqiang Wu*
完成单位:厦门大学
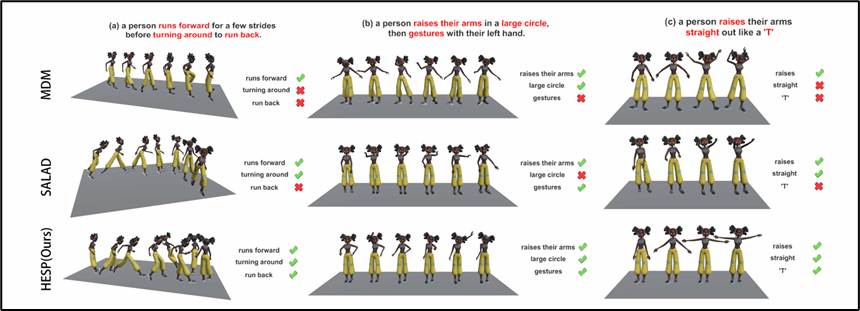
论文简介:文本到动作生成旨在从自然语言描述中合成真实且语义对齐的3D人体动作。现有基于扩散的方法通常依赖各向同性的潜在先验和浅层的跨模态监督,这导致语义纠缠、可控性有限以及可解释性差。我们提出了HESP,一种统一的扩散框架,通过分层增强语义先验,实现解耦的文本驱动动作生成。HESP的自适应高斯变分自编码器(AG-VAE),将潜在动作流形结构化为多个语义一致的子流形,从而实现可解释且可控的动作表示。为了进一步桥接语言与运动语义,我们设计了动态跨模态记忆(DCMM)模块用于自适应语义融合,并引入分层跨模态注意(HCA)机制以捕捉多层次的文本–动作对应关系。在HumanML3D和KIT-ML上的大量实验表明,HESP始终优于最先进的基线方法如SALAD、MoMask和MDM,在保持更高多样性和物理合理性的同时实现了性能提升。此外,HESP的结构化潜在空间提供了可解释的簇,揭示了不同动作类别之间清晰的语义边界。
论文题目:15、RaSE-KGC: A Relation-Aware Segment Encoding Approach for Knowledge Graph Completion
录用类型:ICDE 2026, Main Track
论文作者:Chenxiao Lin, Ye Luo, Kunhong Liu, Qingqiang Wu*
完成单位:厦门大学
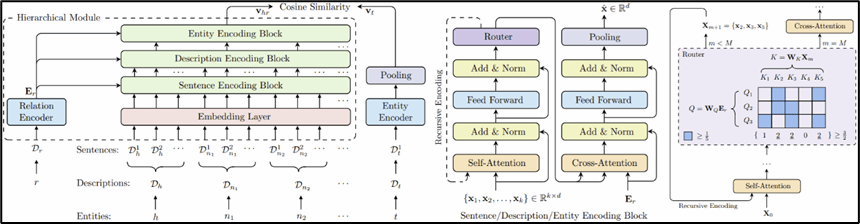
论文简介:面向知识图谱补全中的长文本实体描述处理问题,传统编码网络难以完整表示长文本语义,导致关系预测准确性受限。多层级交叉注意力机制作为增强文本建模的有效技术,旨在提升模型对长文本中关键信息的捕获能力。现有基于预训练语言模型的方法虽能编码文本,但对长实体描述缺乏自适应聚焦机制,无法有效利用长文本中的分布式线索,造成表示不完整。因此,以常数级额外资源开销实现长文本的完整语义表示,成为提升知识图谱补全性能的核心挑战。针对上述痛点,本文创新提出基于多层级交叉注意力的高效编码框架,将查询中的关系作为注意力Query自适应捕获长文本中的关键词与关键句。其核心包括:通过层级化Query-Key交互,动态聚焦长文本中的语义重心;利用循环编码特性实现超大规模知识图谱的文本优化与存储压缩。实验表明该框架在三个基准测试集上平均MRR提升6%,与双模型结构方法相比仅消耗常数级额外资源,展现出优异的长文本处理能力与可扩展性,可助力低成本知识图谱应用。
此外,此次被录用的合作论文相关信息如下
论文题目:16、DiffuReason: Enhancing Reasoning Ability for Diffusion Language Models via Monte Carlo Tree Search
录用类型:ICML 2026, Main
论文作者:Yiping Song, Jinyu You, Zhiliang Tian, Jinsong Su, Minlie Huang, Chenping Hou
完成单位:国防科技大学,厦门大学
论文题目:17、CNSL-bench: Benchmarking the Sign Language Understanding Capabilities of MLLMs on Chinese National Sign Language
录用类型:ACL 2026, Main, Long paper
论文作者:Rui Zhao, Xuewen Zhong, Xiaoyun Zheng, Jinsong Su, Yidong Chen
完成单位:厦门大学
论文题目:18、Selective Contrastive Learning For Gloss Free Sign Language Translation
录用类型:ACL 2026, Main, Long paper
论文作者:Changhao Lai, Rui Zhao, Xuewen Zhong, Jinsong Su, Yidong Chen
完成单位:厦门大学
论文题目:19、DetectRL-X: Towards Reliable Multilingual and Real-World LLM-Generated Text Detection
录用类型:ACL 2026, Main, Long paper
论文作者:Junchao Wu, Yefeng Liu, Chenyu Zhu, Hao Zhang, Zeyu Wu, Tianqi Shi, Yichao Du, Longyue Wang, Weihua Luo, Jinsong Su, Derek F. Wong
完成单位:澳门大学,厦门大学等
论文题目:20、GIFT: Guided Fine-Tuning and Transfer for Enhancing Instruction-Tuned Language Models
录用类型:ACL 2026, Main, Long paper
论文作者:Zhiwen Ruan, Yichao Du, Jianjie Zheng, Longyue Wang, Yun Chen, Peng Li, Jinsong Su, Yang Liu, Guanhua Chen
完成单位:南方科技大学,厦门大学等
论文题目:21、CEMT:Controllable Element-Oriented Machine Translation via Structured Linguistic Reasoning
录用类型:ACL 2026, Findings, Long paper
论文作者:Lingling Shi, Haoyu Jin, Ruiyu Fang, Shuangyong Song, Jinsong Su, Yongxiang Li, Xuelong Li
完成单位:中国电信研究院,厦门大学等






