近日,计算机图形学与多媒体国际会议ICASSP 2026公布录用结果,我中心10篇论文被录用。ICASSP会议全称为International Conference on Acoustics, Speech and Signal Processing,在CCF学术推荐列表中被认定为B类会议。会议将于2026年5月4日至8日在西班牙巴塞罗那举行。ICASSP 2026共收到11120篇有效投稿,录用率约为40%。此次被录用的论文的相关信息如下:
论文题目:Gaussian Splatting with Hybrid Deformation and Multi-Scale Depth Regularization for Dynamic Single-View Video Reconstruction
作者:Ying Ye, Xian Wu, Jintian Li, Junfeng Yao*, Shaoqi Wu, Weixing Xie
完成单位:厦门大学
论文介绍:
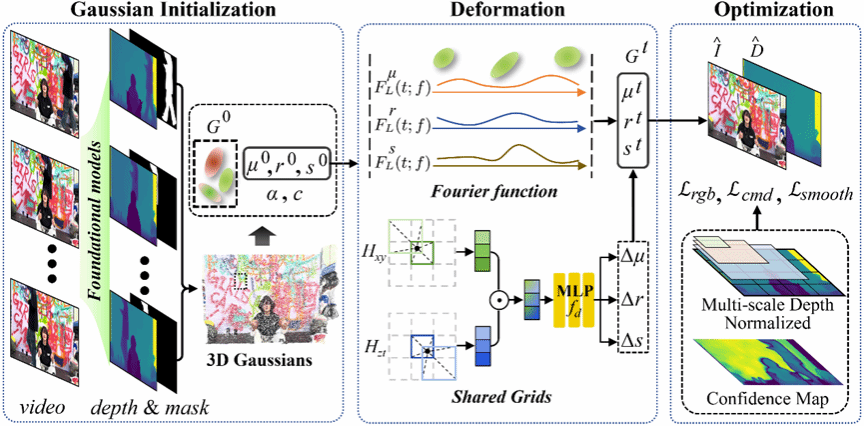
随着 3D Gaussian Splatting(3DGS)和基础模型的发展,基于单目视频的高保真动态场景重建已成为可能。然而,现有的 3DGS 方法主要侧重于快速重建,往往忽视高斯之间的运动交互以及精确的深度生成,从而导致重建质量不理想。为了解决这些问题,我们提出了 GS-HDM,一种新的动态重建框架。首先,我们设计了一种混合可变形表示来刻画复杂的运动交互:结合傅里叶函数与共享哈希网格,分别用于建模单个高斯的运动以及高斯之间的时空交互。其次,为了获得准确且清晰的深度结果,我们提出了一种多尺度深度正则化策略,引导网络在不同尺度上学习深度先验,同时利用置信度权重来缓解来自基础模型的深度噪声。最后,我们提出了一种高效的高斯初始化策略,用于生成稠密的几何先验,进一步提升 GS-HDM 的整体性能。大量实验结果表明,我们的方法在照片级真实感渲染和高精度深度重建方面均优于现有方法。
论文题目:Foundation Models-Guided Multi-Level Motion Decoupling via Gaussian Splatting for Monocular Video Reconstruction
作者:Ying Ye, Xian Wu, Jintian Li, Junfeng Yao*, Yanchen Lin, Youhong Peng, Weixing Xie
完成单位:厦门大学
论文介绍:
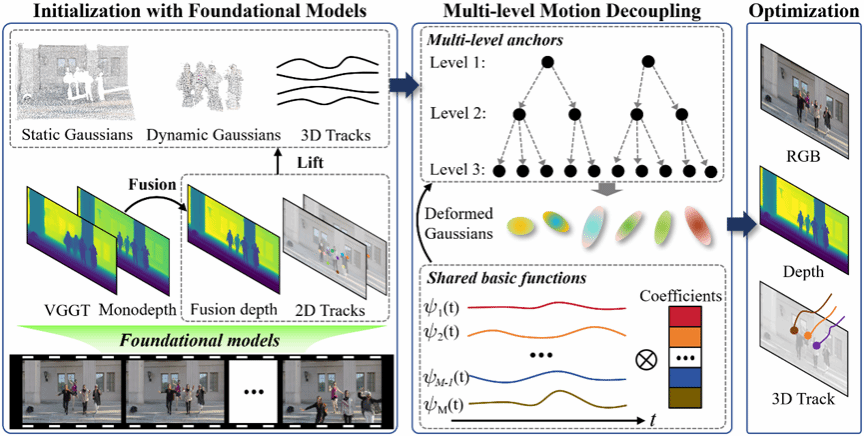
基于单目视频的新视角合成(Novel View Synthesis,NVS)由于其本质上的不适定性和欠约束特性,是一项极具挑战性的任务。现有基于 3D Gaussian Splatting(3DGS)的方法往往缺乏有效的运动表示和一致的先验约束,在单目条件下会显著降低合成视图的质量。为了解决上述问题,我们提出了一种新的高保真 NVS 框架——MMD-GS。首先,我们提出多层级可变形锚点作为运动表示,用于驱动高斯的形变。这种结构化表示能够有效解耦复杂运动,使网络能够在多个层级上捕获形变信息。此外,通过在不同锚点之间共享运动基函数的机制,进一步促进了高斯形变的平滑性。其次,针对几何线索受限的问题,我们设计了一种深度融合策略,将来自不同基础模型的互补先验进行整合。该策略为场景提供了鲁棒的初始化和一致的监督,从而增强了跨视角的一致性。大量实验结果表明,MMD-GS 在新视角合成任务上优于现有方法。
论文题目:STD-Gaussians: Spatio-Temporal Decoupled Gaussian Splatting for Single-View Dynamic Scene Reconstruction
作者: Xian Wu, Ying Ye, Jintian Li, Junfeng Yao*, Jinwen Li, Weixing Xie
完成单位:厦门大学
论文介绍:
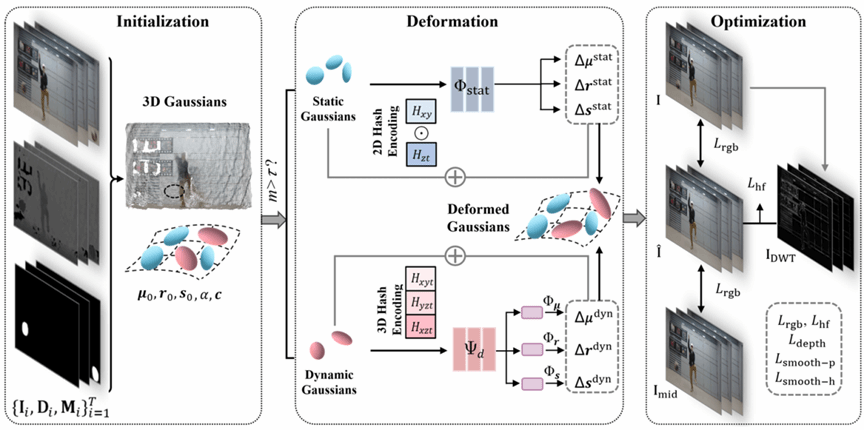
随着社交平台上短视频与直播内容的迅速普及,从单视角视频中高质量重建动态场景已成为计算机视觉与图形学领域的一项关键而极具挑战性的任务。受限于视角信息不足和动态遮挡,现有方法在单视角条件下往往难以兼顾重建质量与渲染效率。针对这一问题,我们提出了一种新的单视角动态场景重建框架——STD-Gaussians(Spatio-Temporal Decoupled Gaussian Splatting)。基于 3D Gaussian Splatting 表示,通过引入置信度感知的迭代高斯初始化(CAI-Gaussian Initialization),有效融合多帧深度与颜色信息,生成完整且稳定的初始点云,显著缓解动态遮挡带来的信息缺失。在此基础上,STD-Gaussians 进一步提出时空解耦的高斯变形建模机制,利用可学习的运动属性将静态与动态高斯进行区分建模,并分别采用高效的编码策略,从而在保持实时渲染效率的同时,提升对非刚性运动和复杂动态的表达能力。此外,时空增强重建策略(STAR)通过频域感知加权与基于运动的时间监督,强化高频细节和大幅运动区域的重建效果。大量实验结果表明,STD-Gaussians 在多种单视角动态视频场景中渲染质量均优于现有方法且保持较快的渲染速度,并具备动态遮挡物移除能力,提供了一种高效且鲁棒的新解决方案。
论文标题:Learning Motion Trends in Gaussian Splatting for Monocular Dynamic Reconstruction
作者:Rui Xie†, Bingbing Hu †, Yukun Cui, Mingyu Shao, Junfeng Yao*
完成单位:厦门大学, 兰卡斯特大学
论文介绍:
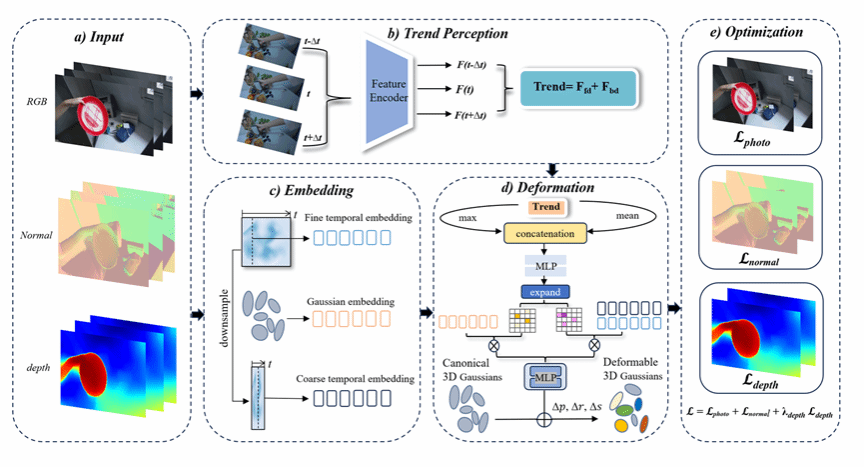
随着 3D Gaussian Splatting(3DGS) 技术的发展,动态场景三维重建取得了显著进展。然而,现有方法通常对每一帧的形变进行独立建模,缺乏显式的时空一致性约束,从而限制了整体重建质量的进一步提升。此外,在单目设置下,面对复杂和非刚性运动时,现有方法仍然面临较大挑战。针对上述问题,本文提出了一种面向单目动态场景重建的全新框架。该方法通过建模相邻时间帧中高斯基元的运动趋势,并利用注意力机制对高斯表示特征与时间特征进行联合增强,从而显式引入时序关联信息。进一步地,我们将整体形变分解为粗层与细层两个阶段,以更有效地刻画复杂运动模式。与此同时,引入由深度图与法向图构建的几何先验,对优化过程进行正则化约束,从而提升几何一致性与重建稳定性。在多个真实世界数据集上的大量实验结果表明,所提出的方法在重建质量上达到了当前最优水平。
论文题目:OTD: DIFFUSION ON OT-STRUCTURED POINT CLOUDS FOR 3D SHAPE GENERATION
作者: Tianhai Sun, Feipeng Rong, Junfeng Yao*
完成单位:厦门大学
论文介绍:
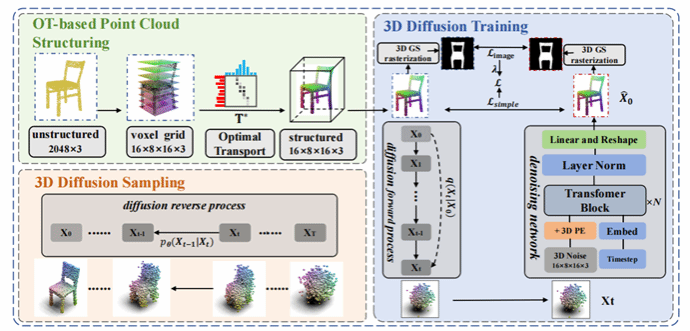
本文针对三维点云生成中点分布稀疏、结构无序以及扩散模型训练和采样效率受限等问题,提出了一种基于最优传输引导的扩散式点云生成方法(OTD)。本文通过引入最优传输机制,将无序点云映射至预定义的规则体素网格中,在保持原有几何结构的同时实现点云的结构化表示,从而降低数据复杂度并提升扩散模型对点分布的建模能力。在此基础上,本文进一步设计了一种面向点云生成的图像级监督损失,利用可微渲染对生成结果进行约束,以改善传统 L2 损失下局部细节模糊和噪声伪影的问题。实验结果表明,本文方法在 ShapeNet 数据集上能够生成更高质量且多样化的三维点云,并在训练时间和采样效率方面相较现有扩散式点云生成方法具有明显优势。
论文题目:Topological Growth Serialization-based Mamba for 3D Point Clouds
作者:Chunyang Huang, Jinwen Li, Mengyuan Ge, Yong Yang*
完成单位:厦门大学
论文介绍:
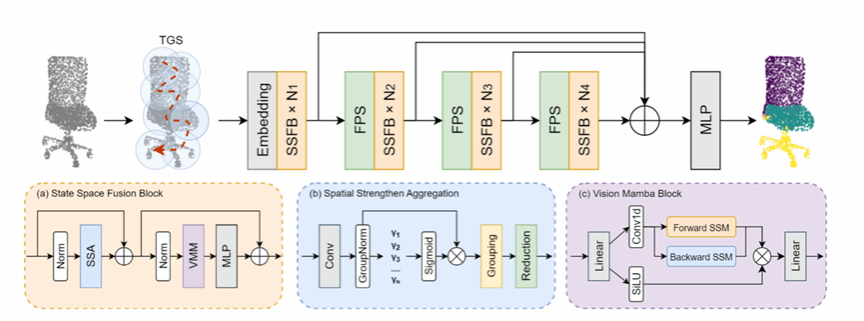
现有三维点云分析骨干网络在平衡全局感受野建模与计算效率方面面临巨大挑战,限制了其在自动驾驶、机器人和AR等领域的实际应用 。虽然近期提出的 Mamba 模型(基于状态空间模型 SSM)展示了以线性复杂度进行长程依赖建模的巨大潜力,但在处理无序点云时,仍存在“相邻点遗忘”和“空间信息冗余”等局限性 。为此,本文提出了一种名为 TGM(Topological Growth Mamba) 的轻量级骨干网络 。首先,针对点云序列化导致的空间连续性破坏问题,我们设计了拓扑增长序列化(Topological Growth Serialization, TGS)方法,通过在 k-NN 图上进行深度优先遍历,有效保留了点序列的拓扑连续性,使模型能更精准地捕获 3D 空间的长程关系 。其次,引入局部空间增强算子(Spatial Strengthen Aggregation, SSA),在增强局部特征提取的同时,有效过滤了不规则点云中的冗余空间信息 。最后,通过设计的状态空间融合模块(State Space Fusion Block, SSFB),将 SSA 与双向 SSM 深度集成,实现了局部与全局建模的有机结合 。
论文题目:Scaling Sentiment Strength via Sentiment Mixing
作者:Zhongquan Jian+, Ke Yao+, Bingbing Hu, Shaopan Wang, Qingqiang Wu*, Junfeng Yao*
完成单位:闽江大学,厦门大学
论文介绍:
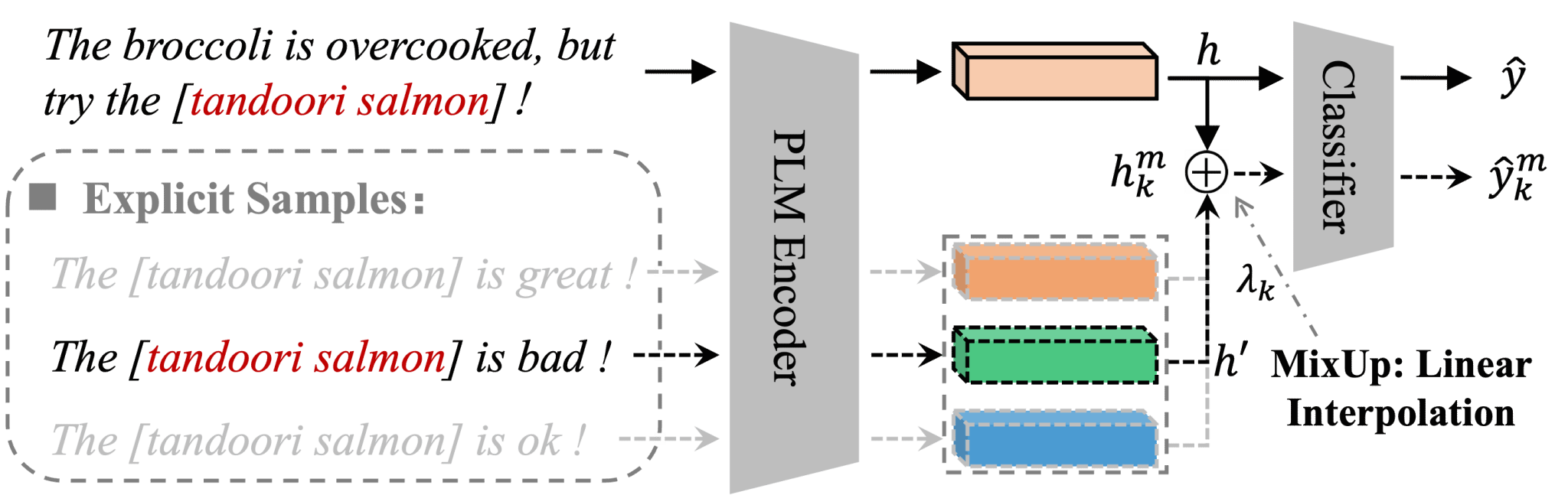
识别隐式情感仍是方面级情感分类(Aspect-level Sentiment Classification, ALSC) 任务中的核心挑战。在这类任务中,情感极性不会通过情感词直接表达,导致模型难以精准捕捉情感线索。本文提出一种简洁且高效的方法--SentiMix,该方法通过情感混合实现情感强度的增强,以此提升模型检测和放大情感线索的能力,尤其适用于表达模糊的句子。具体而言,SentiMix会引入不同极性的原型情感词,构建出情感显式的辅助句子,再将其与原始评论语句进行融合,生成包含混合情感信号的增强表征。基于这类增强信号开展训练,模型能够放大模糊表达的情感强度,从而提升对语境依赖型情感歧义的处理能力。在三个公开 ALSC 数据集上的大量实验验证了SentiMix方法的优越性,同时消融实验也证实:情感尺度化增强机制对提升隐式情感理解能力具有显著效果。
论文题目:DTPE: Document Tree Parsing for Efficient Document-Level Relation Extraction with LLM-Based Data Refinement
作者:Zhicheng Wu, Rong Wang, Fan Gao, Qingqiang Wu, Meihong Wang
完成单位:厦门大学
论文介绍:
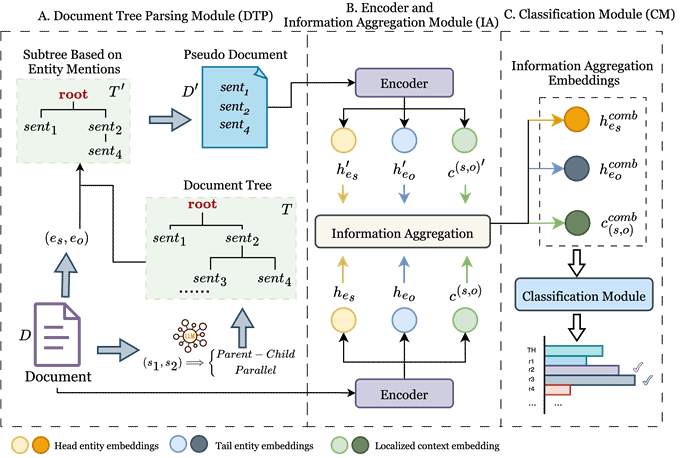
随着非结构化文本分析需求的日益增长,从长文档中识别实体间复杂语义关系的文档级关系抽取(DocRE)任务,已成为信息抽取领域的一项关键而极具挑战性的课题。受限于关系证据的局部化特征与长文本的冗余性,现有将整篇文档作为输入的方法往往引入大量无关上下文噪声,导致模型在处理长距离依赖时难以兼顾抽取精度与推理效率。针对这一问题,我们提出了一种新的文档级关系抽取框架——DTPE(Document Tree Parsing for Efficient Document-level Relation Extraction)。该框架融合了大语言模型(LLM)与 Transformer 架构,首先引入文档树解析模块(Document Tree Parsing Module),利用LLM 将非结构化文档解析为具有层级结构的文档树。针对每一对实体,通过构建仅包含关键证据的最简子树并生成精简的“伪文档”(Pseudo-document),在显著降低输入长度的同时有效保留了核心上下文信息。在此基础上,DTPE 进一步引入互补的信息聚合模块(Information Aggregation Module),通过整合原始文档的全局特征,弥补了局部视角的潜在信息缺失。此外,基于 LLM 的语料库精炼策略(Corpus Refinement via LLM)通过自动修正远程监督数据中的噪声标签,进一步提升了预训练阶段的数据质量与模型鲁棒性。大量实验结果表明,DTPE 在DocRED 和Re-DocRED等主流数据集上均取得了优于现有方法的SOTA 性能,特别是在长文档场景下优势显著,提供了一种高效且精准的新解决方案。
论文题目:SCFusion: Semantic and Contextual Fusion for Document-level Event Argument Extraction
作者:Rong Wang, Zhicheng Wu, Fan Gao, Qingqiang Wu∗, Meihong Wang∗
完成单位:厦门大学
论文介绍:
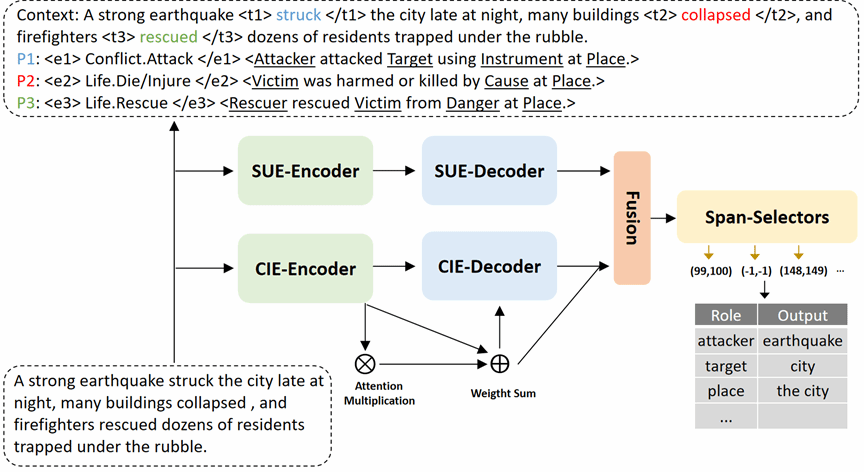
文档级事件论元抽取(Document-level Event Argument Extraction, EAE)旨在在整个文档范围内,给定事件触发词识别其对应的论元。现实世界的文本通常包含多个相互关联的事件,然而现有方法大多侧重于单事件建模或局部触发词–角色交互,这使得模型容易产生角色混淆,且难以捕获跨事件的依赖关系。为了解决上述问题,我们提出了一种统一的框架,引入多事件提示机制,对多个事件进行联合处理,从而更好地建模事件之间的关联关系。进一步地,我们设计了两个互补的模块:语义理解增强(Semantic Understanding Enhancement, SUE)模块,通过将论元槽位与相关词元对齐以减少语义歧义;以及上下文信息增强(Context Information Enhancement, CIE)模块,用于聚合跨句子和跨事件的信息信号,以支持文档级推理。此外,我们提出了一种基于概率的动态融合机制,能够自适应地平衡SUE 模块的语义精确性与CIE 模块的上下文鲁棒性。在三个基准数据集上的大量实验结果表明,该方法在强基线模型之上取得了显著性能提升,验证了所提出方法的有效性。
论文题目:DR.Roleplay: Role-play LLM with Direct Preference Optimization and Retrieval-Augmented Generation
作者:Yuchen Yang, Qi Chen, Zhengyuan Pan, Qingqi Hong*, Qingqiang Wu*
完成单位:厦门大学
论文介绍:
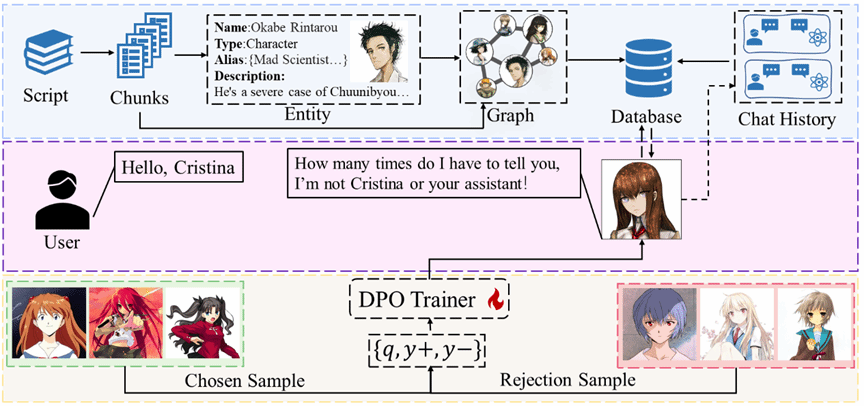
近年来,大型语言模型(LLMs)因其理解人类指令并生成高质量文本的能力,在角色扮演领域得到广泛应用。然而,开发高效的角色扮演型LLMs需要准确检索背景故事与对话历史,同时生成符合角色人设的内容。我们提出一种融合检索增强生成(Retrieval-Augmented Generation,RAG)与直接偏好优化(Direct Preference Optimization, DPO)的统一框架,以解决知识保留与人格一致性难题。RAG通过知识图谱和向量数据库管理角色知识与对话历史,DPO则优化模型策略以增强角色表现力。通过训练对比性角色对话,本框架显著提升了人格一致性并减少了幻觉现象。实验结果表明,DR.Roleplay在角色一致性与对话生成质量方面显著优于基线方法。






