近日,我中心8篇论文被第40届人工智能年度大会AAAI 2026录用。AAAI The 40th Annual AAAI Conference on Artificial Intelligence是人工智能方向的顶级学术会议,被中国计算机学会(CCF)评为A类会议。会议将于2026年01月20日至27日在新加坡举行。AAAI 2026共收到23680篇有效投稿,接收4167篇论文,录用率为17.6%。
录用论文的相关信息如下:
论文题目:MDF: A Modality-aware Disentanglement and Fusion Framework for Multimodal Sentiment Analysis
录用类别:AAAI2026, Main Technical Track
作者:Zhongquan Jian+, Wenhan Lv+, Yanhao Chen, Guanran Luo, Wentao Qiu, Shaopan Wang, Qingqiang Wu*
完成单位:闽江学院,厦门大学
论文介绍:
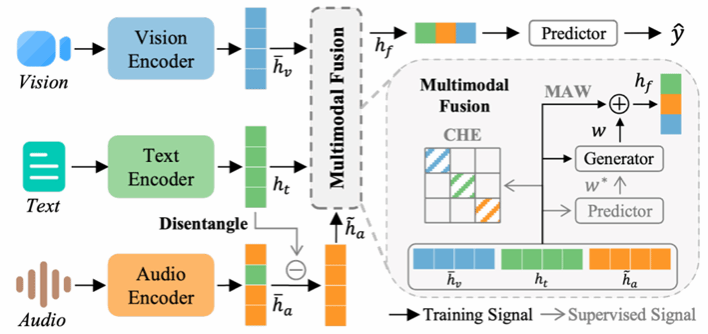
模态间的同质性与异质性是影响多模态融合的关键因素。在多模态情感分析(Multimodal Sentiment Analysis,MSA)中,音频模态中所蕴含的文本信息会与文本模态产生跨模态同质性;相反,文本与视觉模态之间的相互独立性则导致了它们的跨模态异质性。现有的基于解耦(disentangle)的多模态方法虽然通过将模态特征分离到不同子空间中取得了显著性能提升,但往往忽视了不同模态间的跨模态异质性与同质性特征。为此,本文提出了一种新颖的模态感知解耦与融合框架(Modality-aware Disentangle and Fusion,MDF),以探究核心模态特征在多模态情感分析中的作用。具体而言,首先以文本模态为锚点,对音频模态进行解耦,提取其独特的模态特征,从而在文本、音频与视觉三者之间建立跨模态异质性。随后,设计了一个跨模态异质性增强模块(Cross-Modality Heterogeneity Enhancement, CHE),用于进一步精炼这些特征并强化其异质性。最后,引入模态自适应加权模块(Modality Adaptive Weighting, MAW),根据不同模态在情感预测中的潜在贡献,动态分配文本、音频与视觉模态的权重,从而获得更具表现力的多模态表示。在多个基准数据集上的实验结果表明,MDF 具有显著的性能优势,大量的消融实验也验证了其有效性。
论文题目:Stepwise Contrastive Reasoning for Retrieval-Augmented Generation over Knowledge Graphs
录用类别:AAAI2026, Main Technical Track
作者:Chenxiao Lin, Ye Luo*, Kunhong Liu, Qingqiang Wu*
完成单位:厦门大学
论文介绍:
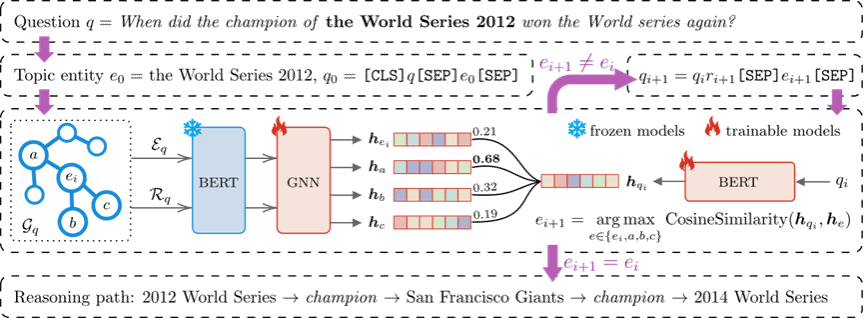
检索增强生成(RAG)通过整合外部知识来提升大型语言模型(LLMs)的推理能力。在现有知识来源中,知识图谱为事实信息提供了结构化且可靠的基础,因此在提升RAG推理准确性的研究中日益受到重视。现有的基于知识图谱的RAG方法大多依赖LLM从知识图谱中提取知识。然而这些方法通常需要耗费高昂的微调成本,且难以处理深层图结构,导致其在多跳推理任务中的效果受限。为应对这些挑战,我们提出逐步对比推理(SCR),一种轻量级框架,通过整合图结构与文本上下文,实现基于知识图谱的高效可解释RAG。SCR将关系消息传递层(用于编码知识图谱实体)与Transformer编码器(用于处理问题文本)相结合,并将推理过程分解为一系列对齐步骤。在每个步骤中,SCR将当前主题实体及其邻接实体与问题表示进行比对,选取最相关实体作为下一个主题实体,并用该实体的文本描述更新问题。此过程持续进行直至选定实体不再变化,表明已定位答案实体。通过逐步对齐机制,SCR使轻量级模型能够在大规模知识图谱上执行准确且可解释的推理。在多个常用知识图谱问答基准上的广泛实验表明,SCR不仅达到当前最先进水平,更能显著提升小型语言模型的推理能力,使其媲美大型语言模型的原始推理水平。
论文题目:Prototype Entropy Alignment: Reinforcing Structured Uncertainty in LLM Reasoning
录用类别:AAAI2026, Main Technical Track
作者:Zhengyuan Pan, Yanhao Chen, Zhongquan Jian, Wanru Zhao, Haonan Ma, Meihong Wang*, Qingqiang Wu*
完成单位:厦门大学,闽江学院,中国科学院大学
论文介绍:
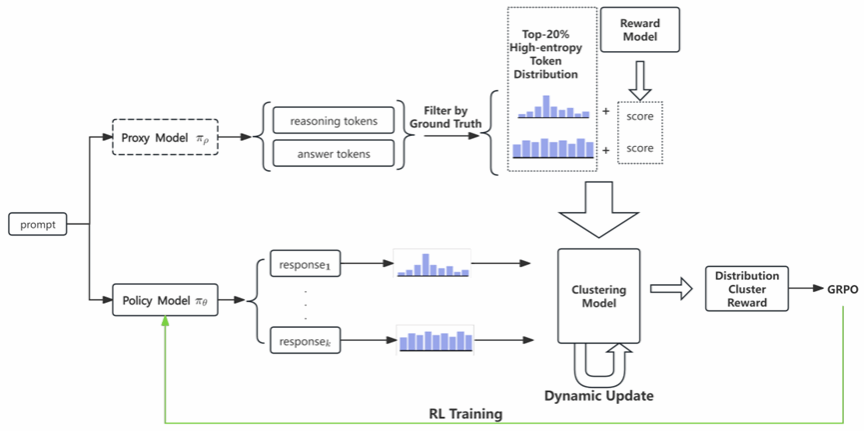
最新研究表明,少数具有高熵值的 token 对大型语言模型(LLMs)的推理质量具有显著影响。受此启发,本文提出了一种原型熵对齐(Prototype Entropy Alignment, PEA)方法,一个将有效推理建模为一组可学习“熵特征签名”的强化学习框架。具体而言,PEA 通过对专家推理轨迹中的不确定性模式进行聚类,动态生成一组原型以识别这些熵特征签名。随后,它通过奖励模型在自身推理过程中与这些不断演化的目标保持一致,从而形成一个自我改进的循环。与传统的基于结果的奖励不同,PEA 提供了一种以过程为导向的补充信号。实验结果表明,这种协同作用至关重要:PEA 在创造性和通用推理任务上显著提升了模型表现,并且在与基于结果的奖励结合时,在数学等结构化任务上达到了当前最优性能。通过奖励模型与多样且动态演化的推理结构保持一致,PEA 为增强大型语言模型推理的深度与适应性提供了一条稳健、无需外部验证器的新途径。
论文题目:MGD: Mesh-guided Gaussians with Diffusion Priors for Dynamic Objects Reconstruction from Monocular RGB-D Video
录用类别:AAAI2026, Main Technical Track
作者:Weixing Xie†, Ying Ye†, Xian Wu, Jintian Li, Bingchuan Li, Yanchen Lin, Junfeng Yao*
完成单位:厦门大学
论文介绍:
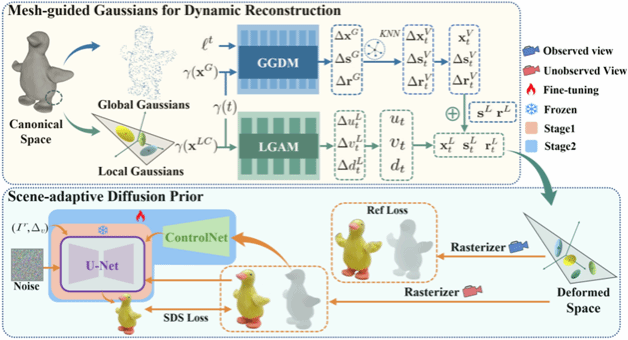
从单目RGB-D视频中重建动态物体对于推进3D视觉应用和提升用户体验至关重要。然而,单目RGB-D视频提供的3D观测信息有限,导致对未观测区域的重建约束不足。尽管近年来将神经隐式曲面与扩散模型相结合取得了进展,但隐式表示的固有局限性以及扩散先验缺乏有效指导,导致动态物体重建出现模糊外观和几何形状不准确的问题。为了解决这一问题,提出了MGD算法,该算法利用场景自适应扩散先验和网格引导高斯函数,实现动态物体(包括未观测区域)的逼真渲染和几何精确重建。MGD重建的动态3D物体使用所提出的网格引导高斯函数进行表示,该函数利用全局高斯函数和局部高斯函数分别捕捉大尺度形变和细粒度外观细节。此外,为了利用深度信息,本文将深度控制网络集成到扩散模型中,并进行场景自适应微调。大量实验表明,MGD 在高保真重建和结构完整性方面均达到了最先进的性能,同时在训练和渲染过程中保持了实时效率。
论文题目:Self-interpretable Subgraph Neural Network With Deep Reinforcement Walk Exploration
录用类别:AAAI2026, Main Technical Track
作者:Jianming Huang, Hiroyuki Kasai
完成单位:厦门大学,早稻田大学
论文介绍:
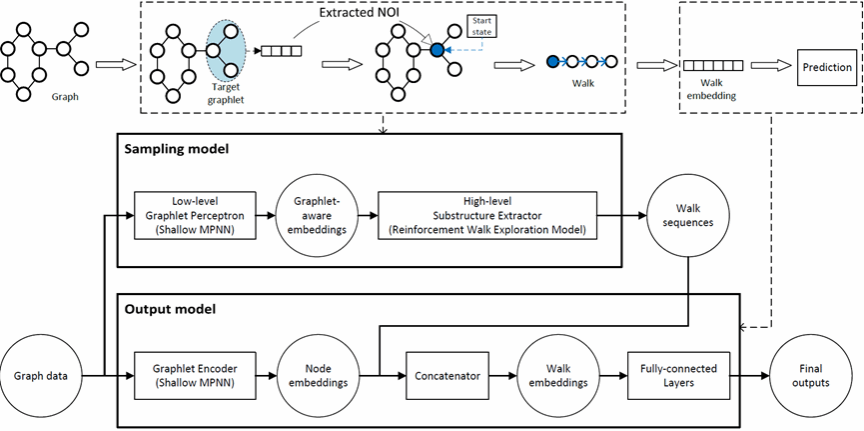
图神经网络(GNNs)面临结构表达能力有限与决策过程不透明的双重挑战。基于子图的图神经网络(SGNNs)近期研究通过子图集成方式提升了模型表达能力,但其依赖预定义采样策略导致可解释性不足与计算效率低下。与此同时,事后图神经网络解释器虽能增强模型可解释性,却难以将解释结论转化为模型改进。本文提出一种创新框架,通过构建具有内在可解释性的SGNNs从根本上解决这一矛盾。我们的核心创新在于构建自解释架构,使解释生成机制与预测过程有机融合。所提出的自解释SGNN采用强化游走探索法(RWE-SGNN)作为数据驱动的采样策略,能够在模型训练过程中动态提取判别性子结构。该强化游走探索模块不仅提供内在可解释性,还具备以下优势:(1)通过游走探索实现高效子结构提取,相较于子图生成方法所需候选数量更少、嵌入更简洁;(2)在保证与传统子图枚举方法等效性的同时,实现多项式级别的复杂度降低。在分子性质预测和社交网络分析任务上的数值评估表明,本方法较现有最先进图神经网络实现了精度提升,案例研究验证了自动识别子结构与领域知识的吻合性。
论文题目:Beyond Passive Critical Thinking: Fostering Proactive Questioning to Enhance Human-AI Collaboration
录用类别:AAAI2026, Main Technical Track
作者:Ante Wang†, Yujie Lin†, Jingyao Liu†, Suhang Wu, Hao Liu, Xinyan Xiao, Jinsong Su*
完成单位:厦门大学,百度
论文介绍:

现有推理模型面对条件缺失问题时容易反复进行假设,而不是主动向用户发起询问,索要缺失的条件。为此,本文基于GSM8K构建了条件缺失问题数据集,包括数据的初步构建和严格的过滤。训练分为两阶段:第一阶段首先利用拒绝采样构造完整推理路径,通过SFT教会LLM在面对条件缺失问题时进行针对性地询问,第二阶段利用GRPO进行强化学习进一步提升模型能力,并激活thinking mode在该情况下的正向作用。训练后的模型在条件缺失问题上表现出色,Qwen3-1.7B的正确率从0.95%提升至70%左右,Qwen3-8B从40%提升至80%左右,Llama3.2-3B-Instruct从0.17%提升至70%左右。同时也具有一定的泛化性和鲁棒性,在正常问题上的能力得到了较好的保持,在加噪的条件缺失问题上也有明显的性能提升。
论文题目:Augmenting Intra-Modal Understanding in MLLMs for Robust Multimodal Keyphrase Generation
录用类别:AAAI2026, Main Technical Track
作者:Jiajun Cao, Qinggang Zhang, Yunbo Tang, Zhishang Xiang, Chang Yang, Jinsong Su*
完成单位:厦门大学、香港理工大学
论文介绍:
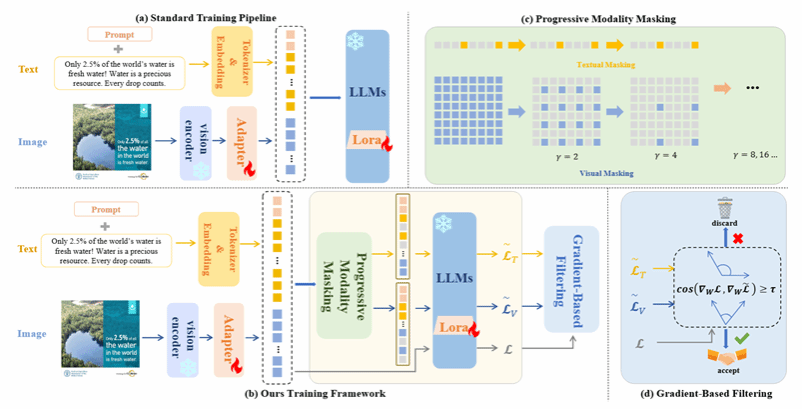
尽管多模态大语言模型(MLLMs)在跨模态理解方面表现突出,但它们在处理噪声、缺失或模态错配的现实场景时表现出两类重要不足:一是弱化的单模态语义建模,即为追求跨模态关联而牺牲了对单一模态中细粒度线索的敏感度;二是模态偏置,某些MLLM倾向于过分依赖文本或视觉,从而忽视另一模态的关键信息。为此,本文提出了 AimKP 框架,以增强MLLM的单模态理解能力并保持跨模态对齐。AimKP包含两个核心部分:(1)渐进模态遮蔽,通过在训练过程中逐步遮蔽模态信息,迫使模型从被破坏的输入中提取细粒度特征;(2)基于梯度的筛选,通过梯度相似性动态剔除噪声样本,防止其影响核心跨模态学习。该方法首次系统性地将MLLM适配至MKP任务,实验结果也表明AimKP在多模态关键词生成任务中显著提升了模型的单模态理解能力和整体鲁棒性,取得了最新的最优性能。
论文题目:PLaST: Towards Paralinguistic-aware Speech Translation
录用类别:AAAI2026, Main Technical Track
作者:Yi Li, Rui Zhao, Ruiquan Zhang, Jinsong Su, Daimeng Wei, Min Zhang, Yidong Chen*
完成单位:厦门大学、华为研究院
论文介绍:
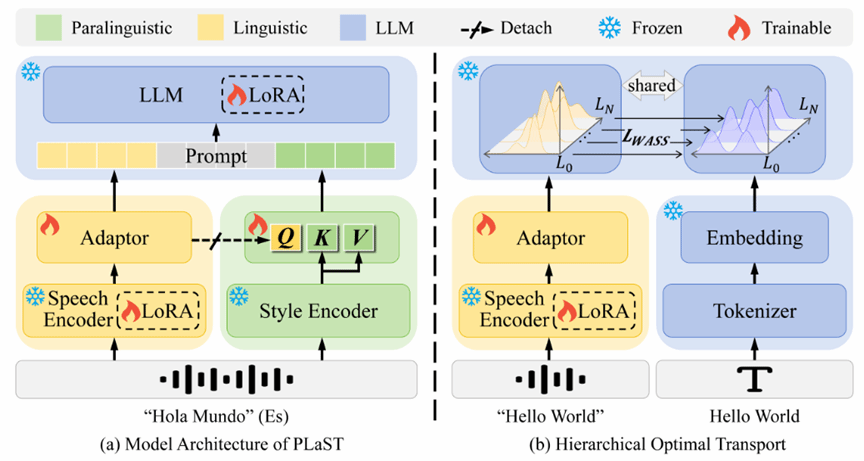
语音翻译(Speech Translation, ST)旨在将源语言语音直接翻译为目标语言文本。然而,语音信号中除语言内容外,还包含语气、情感、强调等副语言线索(paralinguistic cues),这些信息可能显著影响甚至改变语义解读,从而导致不同的翻译结果。现有ST模型普遍缺乏对副语言信息的直接且充分建模,难以全面感知语音中的语用细微差别,限制了翻译性能的进一步提升。为此,本文提出了一种副语言感知的语音翻译框架(ParaLinguistic-aware Speech Translation, PLaST),通过双分支结构显式分离并融合语言与副语言信息。具体而言,PLaST利用语音编码器与风格提取器分别生成语言表征和副语言表征;为进一步获得与文本对齐的纯净语言表征,引入分层最优传输(Hierarchical Optimal Transport)机制对大语言模型解码器的层间输出进行约束;随后,设计基于注意力的检索模块(Attention-based Retrieval, AR),以语言表征为查询,动态检索并精炼副语言信息,实现语义理解与翻译生成的联合引导。在副语言敏感基准ContraProST上的实验表明,PLaST显著优于现有强基线方法;同时在标准语音翻译数据集CoVoST-2上也展现出良好的泛化能力,验证了该方法的有效性与实用性。






