近日,我中心4篇论文被第33届计算机多媒体国际会议ACM Multimedia 2025录用。ACM Multimedia是计算机图形学与多媒体方向的顶级学术会议,被中国计算机学会(CCF)评为A类会议,主要收录多媒体分析、检索、生成、理解与人机交互等方向的高质量论文。会议将于2025年10月27日至31日在爱尔兰都柏林的会议中心举行。
论文简介
论文题目:Sera: Separated Coarse-to-fine Representation Alignment for Cross-subject EEG-based Emotion Recognition
录用类别:Regular Paper
作者:Zhihao Jia+, Meiyan Xu+, Jing Yuan Wang, Ziyu Jia, Yong Li, Xinliang Zhou, Chenyu Liu, Junfeng Yao*, Yi Ding*
完成单位:厦门大学,闽南师范大学,中科院自动化研究所,东南大学,南洋理工大学
论文介绍:

近期在脑电情绪识别研究中的神经心理学启发性模型中,诸如提取空间特征的卷积网络和处理时序依赖的Transformer取得了显著进展。尽管这些方法受益于频带特征和空间相关性等专业知识,却普遍忽略了一个基本事实:脑电信号实则是皮层与皮层下区域等多重神经源活动的复杂混合体。这种混合特性给情绪识别带来本质挑战,尤其在跨被试场景中因个体差异显著而尤为突出。受神经生理学原理启发,我们提出名为Sera的创新框架,通过显式分离神经源活动并实现跨被试表征对齐,提升基于脑电的情绪识别性能。该框架包含两大核心模块:(1)配备多级多分支解码器的变分自编码器(VAE),通过模拟神经信号生成过程将混合脑电解耦为独立神经源;(2)由粗到精的表征对齐模块(CFRA),逐步消除被试间差异。粗粒度对齐采用带域判别器的对抗训练,细粒度对齐则通过协方差矩阵匹配捕捉脑电片段内的时序相关性。在DEAP和DREAMER数据集上的大量实验表明,Sera的准确率优势超越现有最优方法,其有效性与神经生理学基础得到充分验证。模型代码已开源:https://anonymous.4open.science/r/Sera-code-7EC7
论文题目:Gloss Matters: Unlocking the Potential of Non-Autoregressive Sign Language Translation
录用类别:Regular Paper
作者:Zhihao Wang+, Shiyu Liu+, Zhiwei He, Kangjie Zheng, Liangying Shao, Junfeng Yao, Jinsong Su*
完成单位:厦门大学,上海交通大学,北京大学
论文介绍:

虽然非自回归手语翻译(NASLT)模型在推理速度方面具有优势,但其译文质量却明显落后于最先进的自回归手语翻译(ASLT)模型。为了缩小这一质量差距,我们利用手势标注(gloss)来挖掘NASLT模型的潜力。具体而言,我们提出用于手语翻译任务的名为GLevT的模型,它将gloss作为编辑生成文本的初始序列。特别地,为了缓解GLevT的训练和推理之间由于引入gloss导致的不一致性,我们提出了一个双中心学习策略和一种基于关键帧的gloss替换方法改进GLevT的训练,进一步提高GLevT的译文质量。在CSL-Daily数据集上的实验表明,GLevT比其它NASLT模型在BLEU和ROUGE分数上高出约4个点,同时在推理速度上实现了3.46~5.26倍的加速;同时,GLevT与最先进的ASLT模型的翻译性能相当。此外,我们还将GLevT 扩展到无gloss的手语翻译任务上,仅使用49M的参数便取得与最先进的大型模型相当的翻译性能。
论文题目:EditEval: Towards Comprehensive and Automatic Evaluation for Text-guided Video Editing
录用类别:Regular Paper
作者:Bingshuai liu+, Ante Wang+, Zijun Min+, Chenyang Lyu, Longyue Wang, Zhihao Wang, Xu Han, Peng Li, Jinsong Su*
完成单位:厦门大学,上海人工智能实验室,阿里国际,清华大学
论文介绍:

现有视频编辑模型的自动评测指标往往与人工标注结果不一致,迫使研究者依赖耗时且难以客观统一的人工标注。为解决这一痛点,本文构建迄今规模最大的文本指导视频编辑评测基准EditEval,涵盖200段原始视频及1010条多样化文本提示,并从中抽取160个实例以8个主流开源模型生成1280段编辑结果并配以人工标注,从文本忠实度、帧间一致性、视频保真度三大维度全面衡量模型表现;同时提出自动评测方案EditScore,借助多模态大语言模型(MLLM)的推理与理解能力对上述维度统一打分。实验显示目前最佳视频编辑模型在EditEval上平均仅得 3.16/5 分,而在文本忠实度上EditScore(基于LLaVA-One-Vision-7B)与人工标注的Pearson相关性显著优于传统CLIP指标(0.50 vs 0.22),充分彰显任务挑战性与MLLM评测潜力。
论文题目:Seeing Through Ambiguity: Effective Video-guided Machine Translation via Chaotic Fusion and Causally Aligned Spatio-temporal Attention
录用类别:Regular Paper
作者:Jiawei Zheng, Feiyan Liu, Xiaoli Wang *
完成单位:厦门大学
论文介绍:
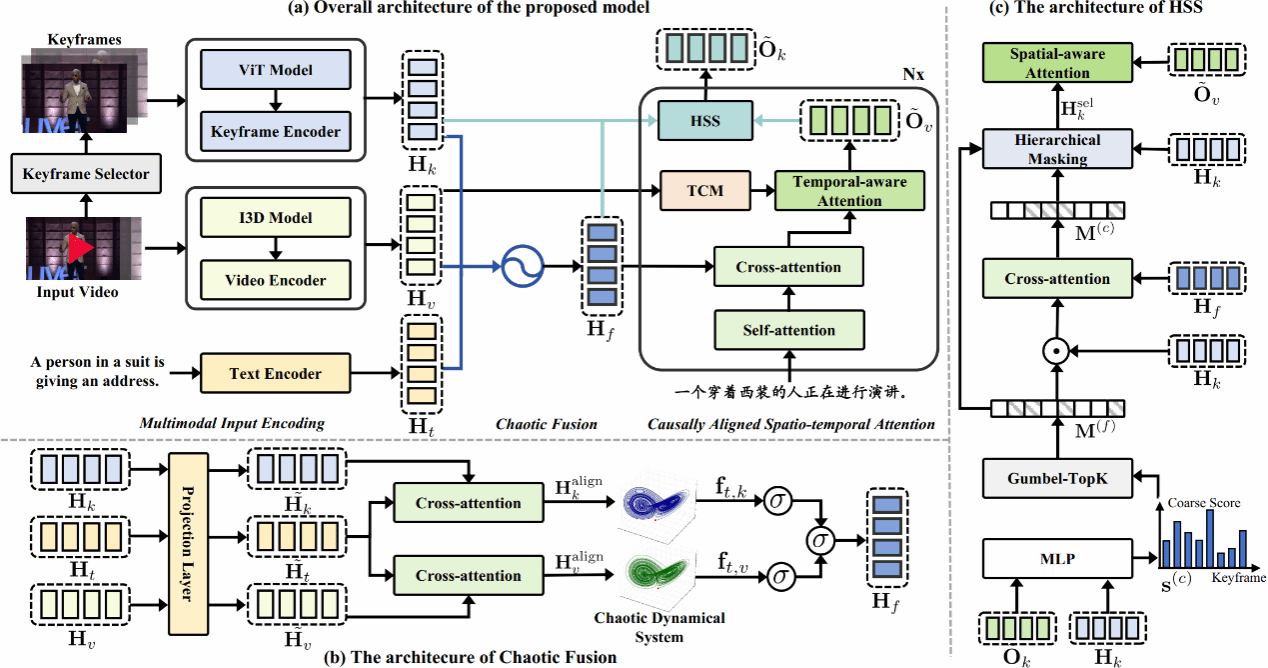
随着多模态人工智能的发展,视频引导机器翻译(Video-guided Machine Translation, VMT)逐渐成为跨模态理解与自然语言处理的重要前沿方向。该任务旨在通过引入视频信息,辅助文本翻译中语义歧义的理解与消解。然而,如何高效整合视频与文本信息、实现准确的视觉对齐仍是该领域的关键挑战。我们提出了一种全新VMT模型,旨在通过引入视频中的动态与静态视觉信息,提升翻译系统在多义词等语义歧义场景下的准确性。针对现有方法中跨模态融合浅层、视觉对齐不精准等问题,我们设计了两项关键机制:混沌融合模块和因果对齐的时空注意力机制。混沌融合通过模拟非线性动态系统,有效整合文本、时序视频和关键帧三种模态,捕捉语义间复杂而细腻的高阶互动关系;而因果对齐机制分别在时间与空间维度精细引导模型关注与当前翻译语境高度相关的视频片段与关键帧,显著提升了视觉落地能力。此外,我们还构建了一个专注于语义消歧的新型评测数据集——PolyVTE,该数据集覆盖了232组视频文本样本,重点包含对多义词的翻译挑战。实验结果表明,我们的模型在通用VMT数据集VATEX及新构建的PolyVTE数据集上均取得领先性能,尤其在需要依赖视觉语境进行多义词消歧的场景中表现突出。模型在BLEU、METEOR 和 COMET 等主流指标上均优于现有主流模型,验证了我们提出的跨模态融合与视觉对齐策略的有效性。这项研究不仅拓展了VMT系统在复杂语义处理方面的能力,也为多模态机器翻译提供了新的思路与基准。






