近日,我中心多篇论文被权威会议IJCAI2025,ICML2025和著名期刊Neural Network录用。ICML会议(International Conference on Machine Learning,国际机器学习会议),是全球人工智能和机器学习领域最具影响力的学术会议之一,在CCF学术推荐列表中认定为A类会议。ICML 2025将于2025年7月在加拿大温哥华举行。IJCAI会议(International Joint Conference on Artificial Intelligence,国际人工智能联合会议)是人工智能领域最具历史和学术声望的国际会议之一,在CCF学术推荐列表中认定为A类会议。IJCAI 2025将于2025年8月在加拿大蒙特利尔举办。Neural Networks是国际著名的学术期刊,专注于神经网络及深度学习领域的前沿研究,在CCF学术推荐列表中认定为B类期刊。
论文简介
论文题目:Enhancing Mixture of Experts with Independent and Collaborative Learning for Long-Tail Visual Recognition
录用会议:IJCAI 2025
作者:Yanhao Chen+, Zhongquan Jian+, Nianxin Ke, Shuhao Hu, Junjie Jiao, Qingqi Hong*, Qingqiang Wu*
完成单位:厦门大学
论文介绍:

论文提出了一种通过独立和协作学习方法增强混合专家模型在长尾视觉识别任务的方法。由于真实世界数据分布中固有的类别不平衡,深度神经网络(DNN)在长尾视觉识别(LTVR)中面临巨大挑战。混合专家模型(MoE)框架已成为解决这些问题的一种有前途的方法。然而,在 MoE 系统中,专家通常是为了优化集体目标而接受训练的,往往忽略了每个专家的个体最优性。由于不同专家的目标并不相互排斥,因此这种个体最优性通常会影响整体性能。为了解决这个问题,本研究提出了一个独立协作学习(ICL)框架,该框架既能促进每位专家的独立优化,又能保持他们的优势,从而协作实现全局最优性能。具体而言,本研究首先引入了多样优化学习(DOL),以增强专家的多样性并强化其表示空间,从而有效提高个体性能。随后,本研究将专家概念化为并行电路的分支,并提出了竞争与协作学习(CoL),通过放大表现更好的专家的梯度来保持个体最优性。CoL 还利用相互蒸馏来促进协作,降低收敛到局部最优的风险。
论文题目:EpiCoder: Encompassing Diversity and Complexity in Code Generation
录用会议:ICML2025
作者:Yaoxiang Wang+, Haoling Li+, Xin Zhang+, Jie Wu, Xiao Liu, Wenxiang Hu, Zhongxin Guo, Yangyu Huang, Ying Xin, Yujiu Yang*, Jinsong Su*, Qi Chen, Scarlett Li
完成单位:厦门大学,清华大学,微软
论文介绍:

现有的大语言模型在代码生成方面已取得显著进展,但在面对复杂结构、多样语义与跨文件依赖等真实开发场景时仍存在能力瓶颈。为了支持更高质量、结构合理、复杂度可控的代码生成任务,本研究提出了一个结构驱动的数据合成框架 EpiCoder,引入“特征树(feature tree)”作为代码语义的中间结构表示,系统性地控制代码片段的结构、语义及跨组件依赖关系。借助这一结构化合成流程,EpiCoder 能够生成可调复杂度、结构清晰且跨语义路径多样化的代码数据,从而有效提升模型在结构化理解与复杂生成任务上的表现。实验证明,EpiCoder 可广泛支持包括模块级代码生成、跨文件建构、语义覆盖增强等任务,并在多个代表性基准任务中显著提升现有代码大模型的性能与泛化能力。
论文题目:Boosting Visual Knowledge-Intensive Training for LVLMs through Causality-driven Visual Object Completion
录用会议:IJCAI2025
作者:Qingguo Hu+, Ante Wang+, Jia Song, Delai Qiu, Qingsong Liu, Jinsong Su*
完成单位:厦门大学,云知声
论文介绍:

本研究提出了一种创新的自我改进框架,用于增强视觉语言模型(LVLMs)的视觉感知与推理能力。该框架基于因果驱动的视觉对象补全任务(CVC),要求以明确的推理链形式,利用图像中的可见上下文信息来推断被遮挡的对象,从而将感知密集的复杂推理能力引入LVLMs。类似于人类通过反复试错来提升解决复杂问题的能力,该框架采用试错学习来强化LVLM对CVC的掌握程度,从而提升其全面的视觉能力。首先,该框架采样LVLM的多个推理路径(试验),然后挑选出对训练有价值的样本,最终将这些自我生成的试验用于LVLM的自我改进。因此,LVLM的视觉能力可以在不依赖人类或更先进 LVLM 的情况下得到全面的自我提升。实验证明,该框架在多个通用测试基准和高难度专项任务上均优于对应的基线模型,尤其在更具挑战性的任务中,如MMVP和Winoground,分别实现了10.0%和8.2%的提升。
论文题目:Towards Better Text Image Machine Translation with Multimodal Codebook and Multi-stage Training
录用期刊:Neural Networks
作者: Zhibin Lan, Jiawei Yu, Shiyu Liu, Junfeng Yao, Degen Huang, Jinsong Su*
完成单位:厦门大学,大连理工大学
论文介绍:
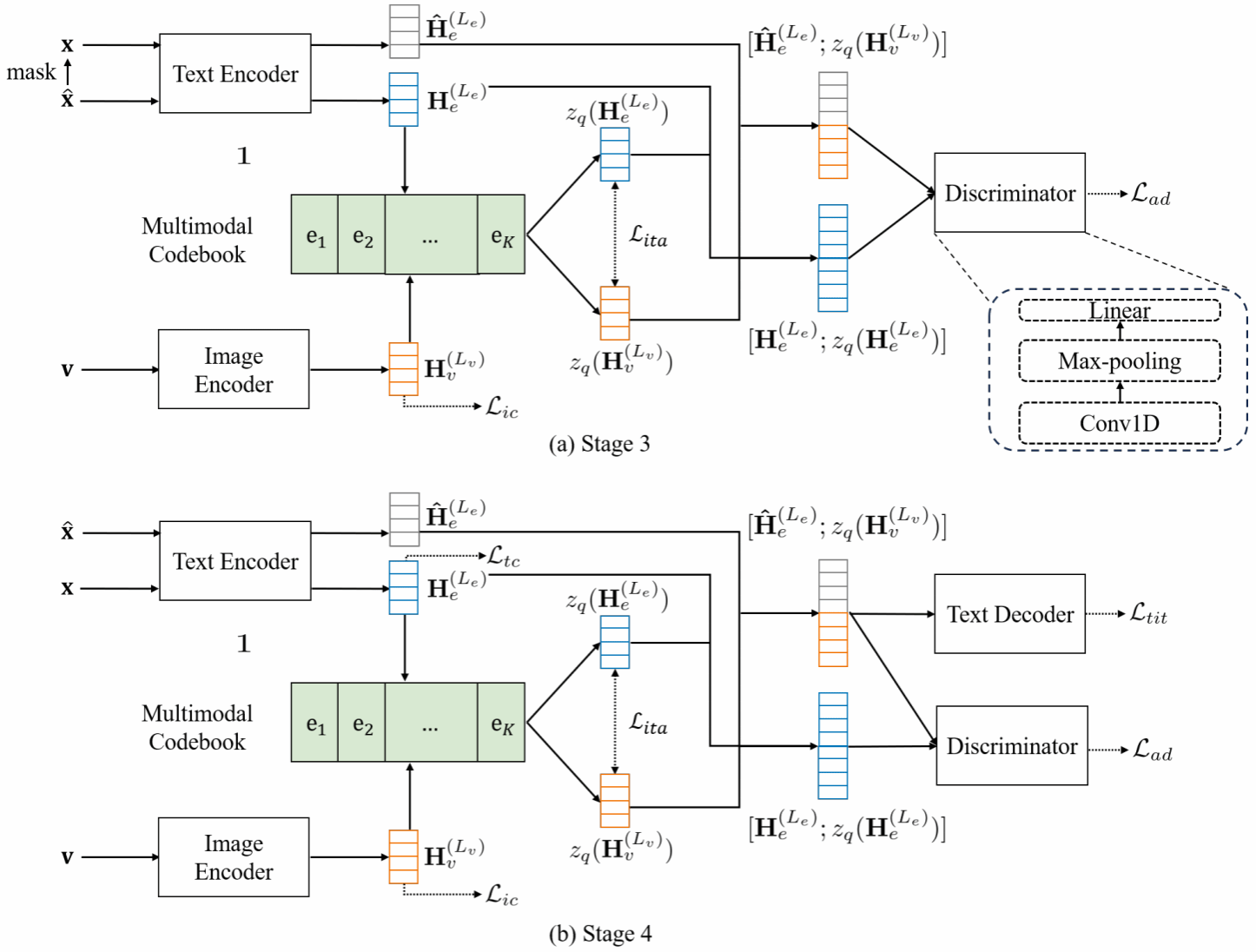
当前图文翻译任务在跨模态理解与语言生成领域受到广泛关注,但现有方法仍面临两大核心挑战:一方面,主流方法普遍采用OCR识别与文本翻译串联的级联结构,导致OCR误识别会严重影响最终翻译结果;另一方面,缺乏大规模、高质量的公开图文翻译数据集也限制了模型能力的进一步提升。为此,本研究人工标注并公开了首个中英图文翻译数据集OCRMT30K,并借助自动翻译工具将其扩展到中德语言对上,为该领域提供了宝贵的训练资源与评测基准。此外,本研究提出了一种基于多模态码本的图文翻译模型,通过引入图像编码器、文本编码器、文本解码器以及可桥接图文语义的多模态代码本,实现了跨模态语义的高效对齐与增强的翻译性能。同时,论文设计了一套多阶段训练框架,充分利用不同类型的数据资源,逐步优化各个模块:先基于双语文本进行文本模块的预训练,接着引入基于码元的掩码翻译任务进一步训练多模态码本与文本编码器和解码器模块,再借助图文对齐与对抗训练方法在OCR数据集上优化图像编码器模块与多模态码本,最后使用图文翻译数据集对整个模型进行微调。实验结果表明,该模型在中英与中德图文翻译任务中均显著优于现有方法,验证了其跨模态建模与阶段训练策略的有效性。






