近日,我中心6篇论文被权威期刊/会议IPM,BIBM 2024和ECAI 2024录用。IPM期刊全称为Information Processing & Management,在CCF学术推荐列表中认定为B类期刊。BIBM会议全称为IEEE International Conference on Bioinformatics and Biomedicine,是生物信息学的权威会议,在CCF学术推荐列表中认定为B类会议。ECAI会议全称为European Conference on Artificial Intelligence,是人工智能的权威会议,在CCF学术推荐列表中认定为B类会议。
论文简介
论文题目: S2CCT: Self-Supervised Collaborative CNN-Transformer for Few-shot Medical Image Segmentation
录用类别:BIBM,Regular paper
作者:周荣洲+,舒子琪+,谢卫星,姚俊锋*,洪清启*
完成单位:厦门大学
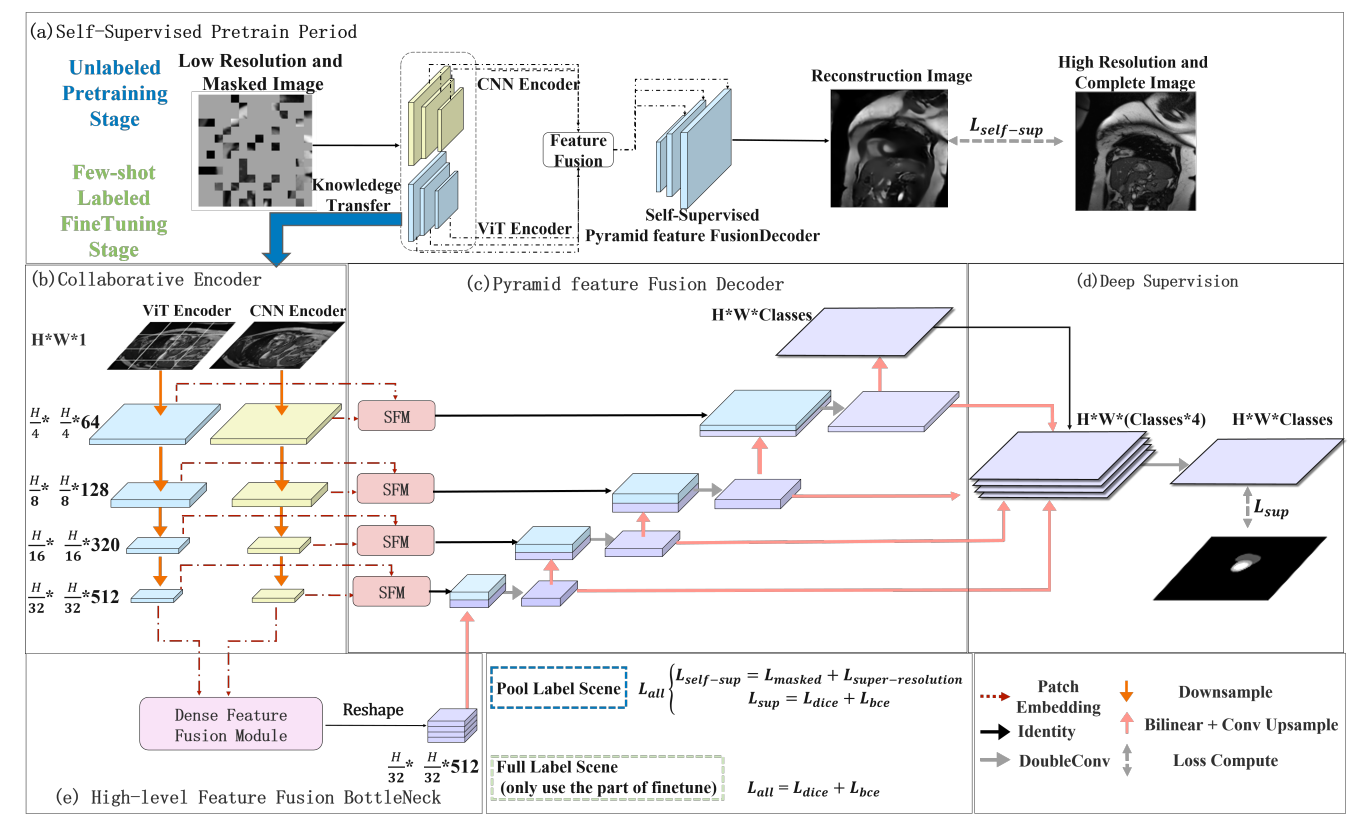
自监督预训练加上微调是少样本学习中的一个强大范式,能够有效利用大量未标注数据。目前的自监督方法通常倾向于使用视觉 Transformer(ViTs),而不是 CNN-Transformer 混合架构,后者通常表现出更优的性能。然而,这种对 ViTs 的依赖可能导致模型对局部特征的感知较差。挑战在于为 CNN-Transformer 这样的混合架构设计合适的代理任务,因为它们在结构上存在显著差异。此外,目前的 CNN-Transformer 混合骨干网络通常是顺序组织的,这在预训练期间阻碍了两者的协作,以及获取强健的表示能力。为了解决这些问题,本文提出了用于少样本医学图像分割的*自监督协作 CNN-Transformer框架。该框架引入了三个创新设计:(1)基于图像掩膜和图像超分辨率的复合代理任务,专为 CNN-Transformer 混合架构设计,使骨干网络在预训练期间获取强健的表示,并能够迁移到下游任务;(2)并行 CNN-Transformer 架构,更好地关注图像中的多尺度特征,使其更适合密集预测任务,如图像分割;(3)稀疏与密集特征融合模块,增强了两个编码器之间的协作。实验表明,S2CCT 在两个公共医学图像分割基准数据集ACDC 和 KiTs19上优于之前的最新方法。
论文题目:CPDT: A Novel Cluster-based Paired Decision Tree for Identifying Biomedical Entity Interactions
录用类别:BIBM, Regular paper
作者:邹嘉禹,武连莲,林伟平,刘昆宏*,徐永*,何松*,伯晓晨*
完成单位:厦门大学,***医学科学院
论文介绍:
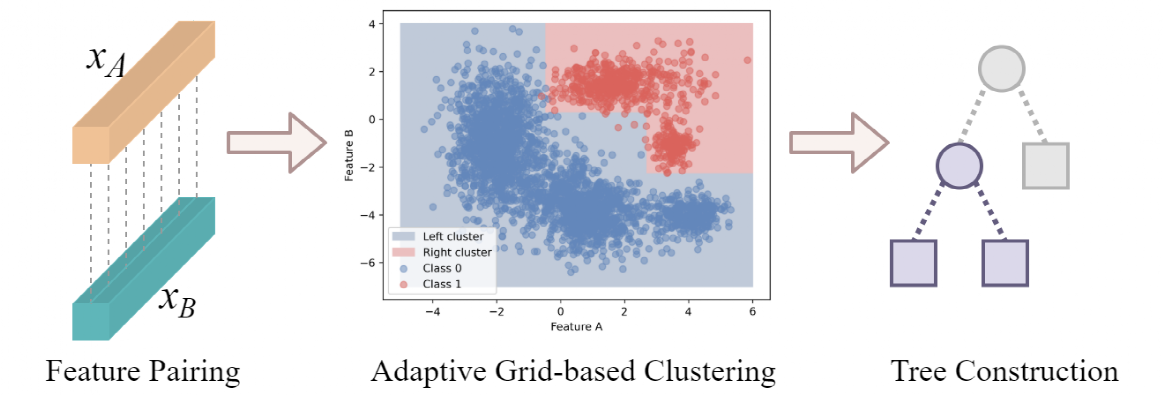
在生物医学领域的交互预测任务中,传统的机器学习算法通常通过独立处理各个特征,而忽略了实体对之间的复杂关系,这种做法在捕捉实体对交互信息时存在一定的不足。为了解决这一问题,本文提出了一种创新的基于聚类的配对决策树模型(CPDT)。该模型通过将实体对的同义特征进行配对,从而构建一个成对特征空间,允许模型同时处理特征对之间的关联信息。CPDT 采用了一种自适应网格聚类算法,该算法以轴平行的方式对成对特征空间进行划分,从而生成更加直观且具解释性的决策边界。这种聚类算法通过利用概率密度函数来动态适应不同特征空间中的数据分布,从而提高了样本划分的精确性和效率。通过在药物联合预测和合成致死性预测任务中的实验验证,CPDT 展现出了优异的性能,显著超越了现有的许多方法。此外,CPDT 还能生成简单且易于解释的决策规则,揭示了生物医学相互作用中的潜在模式。这一特性不仅有助于理解复杂的生物医学交互,还使得该模型在实际应用中具备了更高的可解释性。CPDT 还表现出了识别具有医学意义的分子特征的潜力,进一步表明它在生物医学领域中的应用前景广阔,尤其是在精准医疗和药物研发等方面具有重要的实践价值。
论文题目:Mitigating the Negative Impact of Over-association for Conversational Query Production
录用类别:IPM
作者: 王安特,宋林峰,闵子君,徐戈,王晓黎,姚俊峰,苏劲松*
完成单位:厦门大学,腾讯AI Lab,闽江学院
论文介绍:
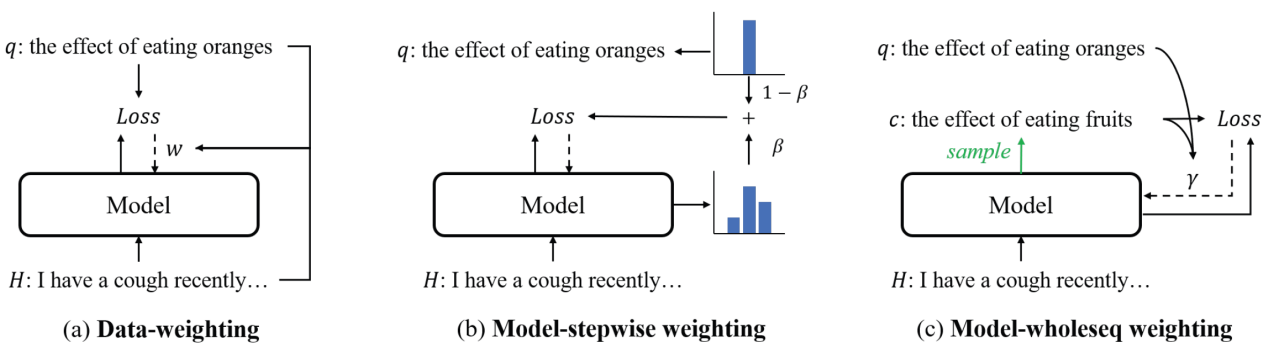
对话查询生成是连接对话系统与搜索引擎的桥梁。该研究首次观察到对话查询生成数据集普遍存在的“过度联想”现象,即人工标注的查询标签与对话上下文联系不紧密,模型难以依据上下文准确推断出目标查询。实验发现,在高“过度联想”的数据子集上训练模型时,更容易引发幻觉现象。为解决该问题,该研究提出多种通过调节数据权重来减少负面影响的方法:1)基于数据。根据标注查询与对话内容的关联程度调整权重;2)基于模型。实验发现,模型生成查询的“过度联想”程度偏低,因此,进一步提出通过自蒸馏与强化学习的方式,基于模型预测与真实标签来调节权重。中英文数据集上的实验均表明,该研究提出的方法不仅能有效提高模型性能,还能加速模型收敛,使数据利用效率提高近十倍。
论文题目:Towards Cross-Modal Text-Molecule Retrieval with Better Modality Alignment
录用类别:BIBM, Regular paper
作者:宋佳,庄婉如,林渝杰,张亮,李春艳,苏劲松*,何松*,伯晓晨*
完成单位:厦门大学,***医学科学院
论文介绍:
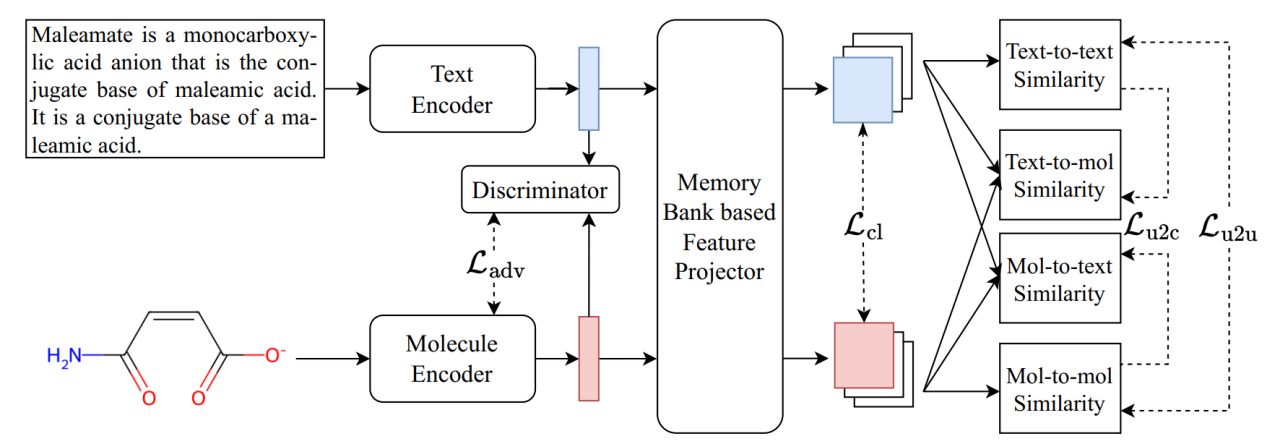
跨模态文本-分子检索模型旨在通过精确匹配文本描述和分子结构来辅助研究人员快速筛选合适的候选分子。然而,先前的研究在处理文本序列和分子图之间的显著差异时,未能充分捕捉模态间的共享特征,并且主要依赖基于一阶相似性的对比学习来实现跨模态对齐,忽略了能够在嵌入空间中捕获更多结构信息的二阶相似性。该研究提出了一个具有双重改进的跨模态文本-分子检索模型。首先,模型在两种模态特定的编码器之上引入了一个基于记忆库的特征投影器,该投影器包含可学习的记忆向量,以更好地提取模态共享特征。其次,在模型训练过程中,计算了两种同模态相似性分布和两种跨模态相似性分布,并通过最小化这些相似性分布之间的距离(即二阶相似性损失)来增强跨模态对齐。实验结果表明,所提出的模型在所有当前任务的数据集上优于现有模型,能够有效减小模态差距。
论文题目:Exploring Optimal Transport-Based Multi-Grained Alignments for Text-Molecule Retrieval
录用类别:BIBM, Regular paper
作者:闵子君+,刘冰帅+,张亮,宋佳,苏劲松*,何松*,伯晓晨*
完成单位:厦门大学,***医学科学院
论文介绍:
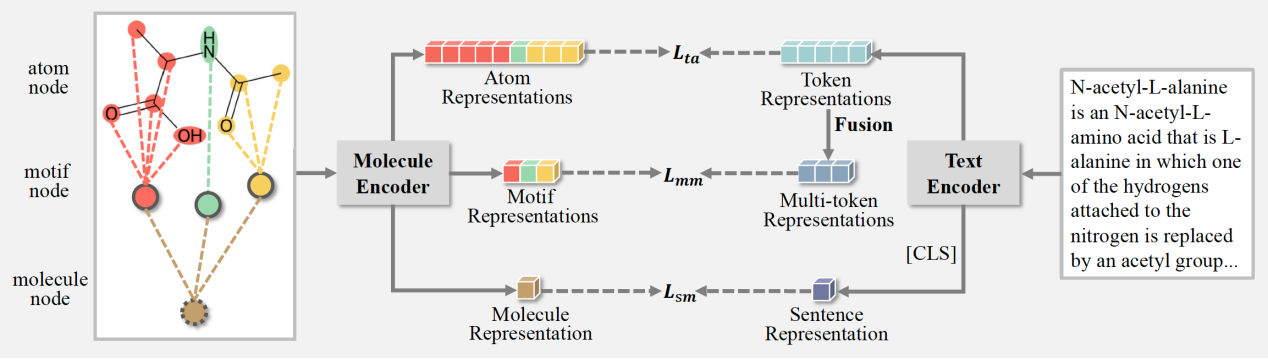
跨模态文本-分子检索任务旨在根据文本描述准确地检索对应的分子结构,从而帮助研究者快速定位合适的候选分子。然而,许多现有的方法忽视了分子细粒度结构中的细节信息。本文提出的模型包括文本编码器和分子编码器:文本编码器用于处理文本描述,生成词元级和句子级的表示;分子被建模为分子异构图,包括原子、子结构和分子节点,以在这三个层次上提取表示。同时,本文应用了最优传输算法来对齐词元和子结构,聚合与同一个子结构表示对齐的多个词元表示,得到多词元表示。本文采用对比学习在三个不同的尺度上对齐跨模态表示:词元-原子、多词元-子结构和句子-分子级别。实验结果表明,本文提出的模型在所有当前任务的数据集上优于现有模型。
论文题目:On the Cultural Gap in Text-to-Image Generation
录用类别:ECAI, Long paper
作者:刘冰帅,王龙跃*,吕晨阳,张勇,苏劲松,史树明,涂兆鹏*
完成单位:厦门大学,腾讯AI Lab,都柏林城市大学
论文介绍:
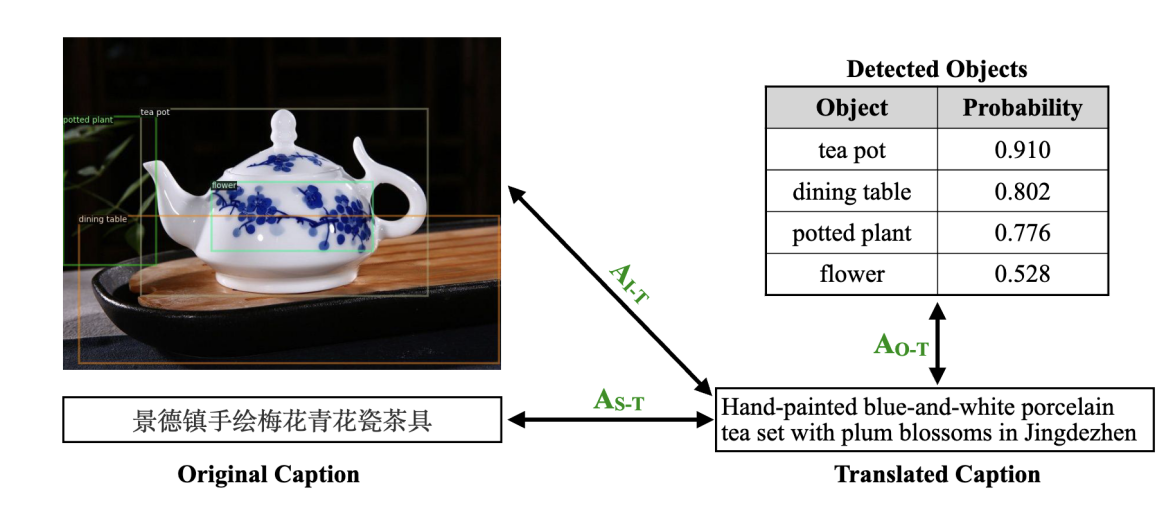
该研究主要聚焦于文本到图像生成中的文化差异问题。训练数据中对特定文化元素的收集较为稀少,导致生成的图像质量在文化相关性方面存在明显差距。尽管现有的文本到图像生成模型展示了不少令人印象深刻但带有偶然性的示例,但目前缺乏一个系统性评估文本到图像生成模型跨文化生成能力的基准。为填补这一空白,本文提出了一个跨文化挑战基准(C3),通过全面的评价标准来衡量模型对目标文化的适应性。通过分析Stable Diffusion模型在C3基准下生成的有缺陷的图像,发现该模型经常无法生成特定的文化对象。因此,本文提出了一种新颖的多模态数据过滤指标,结合了对象-文本对齐,旨在筛选出适合目标文化的微调数据,从而改进文本到图像生成模型的跨文化生成能力。实验结果表明,我们的多模态指标在C3基准上的数据选择性能优于现有指标,其中对象-文本对齐至关重要。






