近日,我中心语言数据知识计算课题组5篇论文被权威会议EMNLP 2024录用。EMNLP会议全称为Conference on Empirical Methods in Natural Language Processing,由国际计算语言学协会ACL举办,是自然语言处理和人工智能领域最重要的学术会议之一,在CCF学术推荐列表中认定为B类会议,CAAI学术推荐列表和清华计算机学术推荐列表中认定为A类会议。EMNLP 2024将于2024年11月12日至11月16日在美国迈阿密举行。
论文简介
论文题目:A Learning Rate Path Switching Training Paradigm for Version Updates of Large Language Models
录用类别:Main, Long paper
作者:王志豪+,刘诗雨+,黄健亨,王征,廖益玄,陈晓昕,姚俊峰,苏劲松*
完成单位:厦门大学,Vivo
论文介绍:
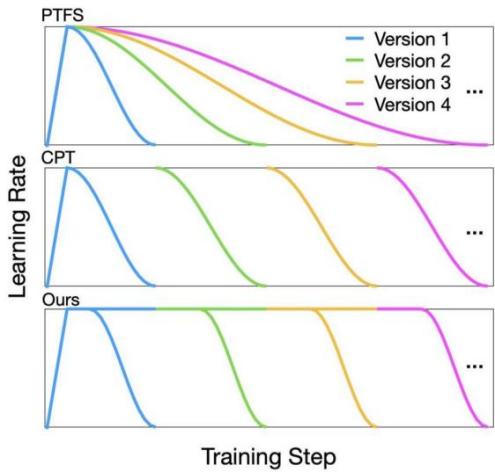
新数据的不断涌现使版本更新成为大语言模型不可或缺的需求。大语言模型版本更新的训练范式包括从头预训练和继续预训练。先导实验表明,从头预训练得到的大语言模型的预训练性能更好,而继续预训练的总训练成本更低,此外,两种范式的性能和训练成本之间的差距随着版本的更新而逐渐扩大。为了分析该现象的原因,我们分析在继续预训练的两个阶段调整学习率的效果:准备初始化检查点(checkpoint)和根据检查点进行预训练。我们发现,第一阶段较大的学习率和第二阶段完整的学习率衰减过程对于大语言模型的版本更新至关重要。因此,我们提出一种学习率路径切换训练范式。如图所示,我们的范式包括一条主路径和多条分支路径,前者以最大学习率预训练大语言模型,后者则是用新增的训练数据更新大语言模型。在训练4个版本的大语言模型时,与从头预训练相比,我们的范式将总训练成本降低至58%,同时保持了相当的预训练性能。此外,我们还验证了我们的范式的通用性,进一步证明了它的实用性。
论文题目:Multi-Level Cross-Modal Alignment for Speech Relation Extraction
录用类别:Main, Long paper
作者:张亮+,杨振+,付彪,陆紫耀,邵良颖,刘诗雨,孟凡东,周杰,王晓黎,苏劲松*
完成单位:厦门大学,微信
论文介绍:
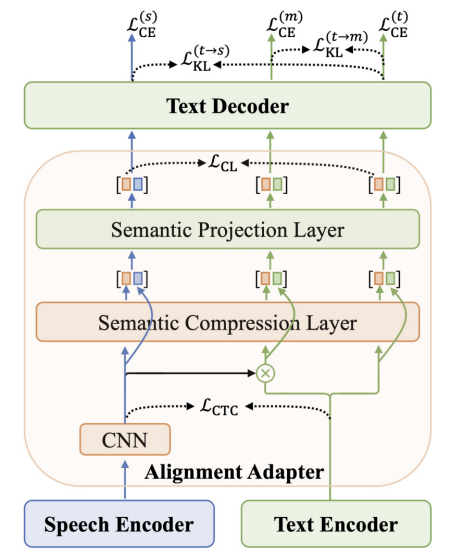
该研究聚焦于一个新的关系抽取任务(语音关系抽取),该任务旨在从输入音频中抽取有价值的关系三元组。由于模态差异和数据稀缺,现有的语音关系抽取模型的性能明显落后于文本关系抽取模型的性能。针对这两个问题,我们首先提出了一个多层次夸模态对齐方法来有效缩小音频模态和文本模态之间的模态差异,从而改善模型生成关系三元组的准确性。同时,我们还引入了一个数据增强策略,该策略能有效地利用现有的大量ASR数据来缓解语音关系抽取中数据稀缺问题。实验结果表明,我们的方法和策略能极大地改善语音关系抽取的性能。
论文题目:One2Set + Large Language Model: Best Partners for Keyphrase Generation
录用类别:Main, Long paper
作者:邵良颖+,张亮+,彭敏龙,马国棋,岳皓,孙明明,苏劲松*
完成单位:厦门大学,百度
论文介绍:
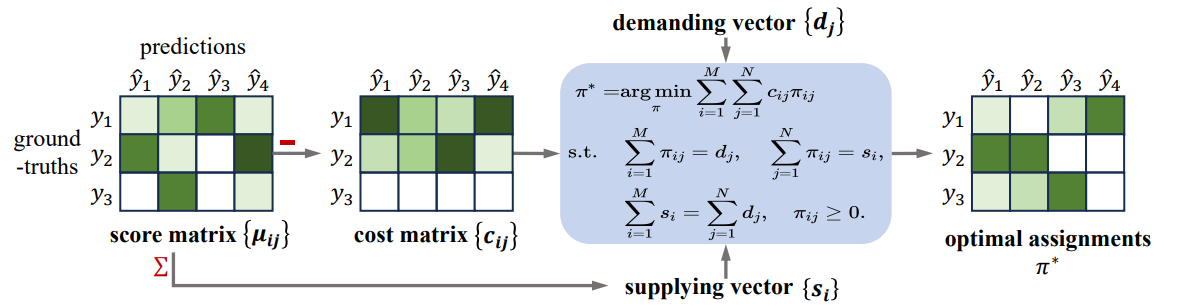
该研究聚焦于关键短语生成任务。该任务旨在为给定文档生成描述核心思想的关键短语。目前该研究领域的现有模型均不能很好地平衡精确度和召回率两个指标,因此文章引入generate-then-select框架将生成拆分成两步,分别利用One2Set模型的高召回和大模型的长序列建模及语义理解能力优化最终性能。文章从两个方面优化生成系统:1)提出基于最优传输的分配策略优化One2Set,使其在同精确度水平下拥有更高的召回率;2)利用LLM作为选择器,将对候选短语的选择转化为序列标注任务建模候选相关性和选择相关性,减少最终关键短语集合中的语义重复。在多个基准数据集上的实验结果均表明该框架的有效性,特别是在缺失类关键短语生成方面。
论文题目:Empowering Backbone Models for Visual Text Generation with Input Granularity Control and Glyph-Aware Training
录用类别:Main, Long paper
作者:李文博,李国豪,蓝志彬,徐薛,庄婉如,刘家辰,肖欣延,苏劲松*
完成单位:厦门大学,百度
论文介绍:
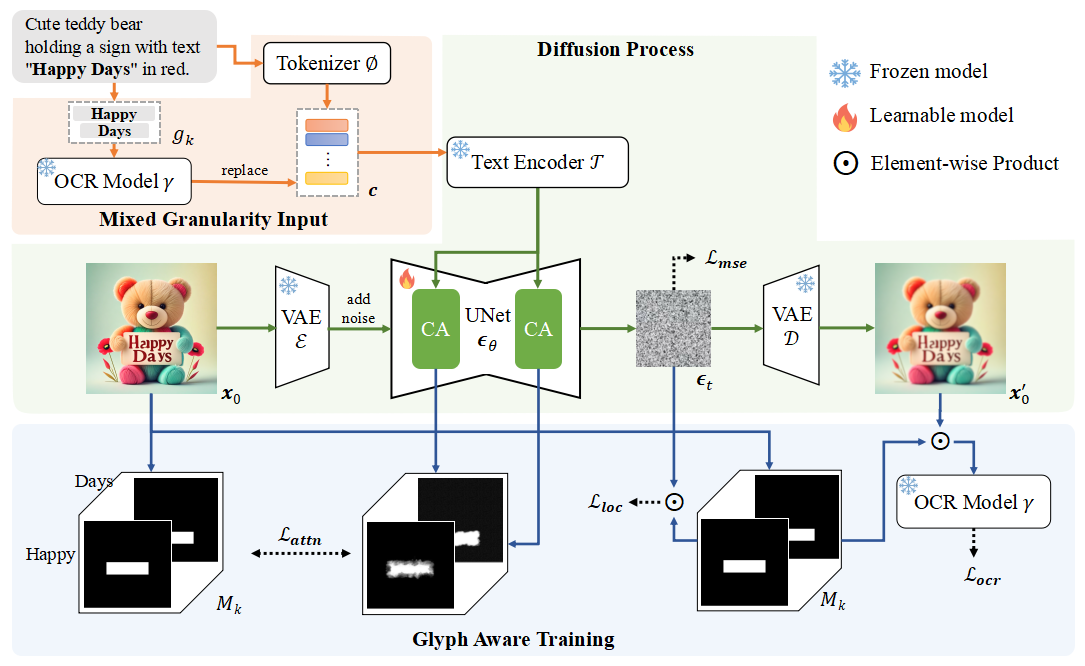
扩散模型在文生图领域取得了长足进步,但始终无法准确的在图片中绘制出文字。该工作聚焦于提升基座扩散模型的图片文字生成能力,在不降低模型整体图片生成质量的前提下,训练模型生成准确,美观,艺术的图片文字,并在中文文字生成上验证了方法的有效性。工作首先从先导实验出发,探究得到BPE分词对模型理解文字字形信息产生了负面影响,以及现有模型的注意力模块未能准确将文字token与图片文字部分进行对应。基于实验发现,文章进行了以下改进:1)提出了混合粒度的输入,将英文文字作为整体输入模型,将中文文字进行汉字级别分词,从而提供了更丰富的字形信息;2)提出了三个训练目标,提升模型对于图片文字区域信息的学习,以及对图片文字区域与文字token之间对应关系的学习。量化实验以及人工评测均表明该方法的有效性。
论文题目:Self-Consistency Boosts Calibration for Math Reasoning
录用类别:Findings, short paper
作者:王安特,宋林峰*,田野,彭宝林,金立峰,米海涛,苏劲松*,余栋
完成单位:厦门大学,腾讯西雅图
论文介绍:
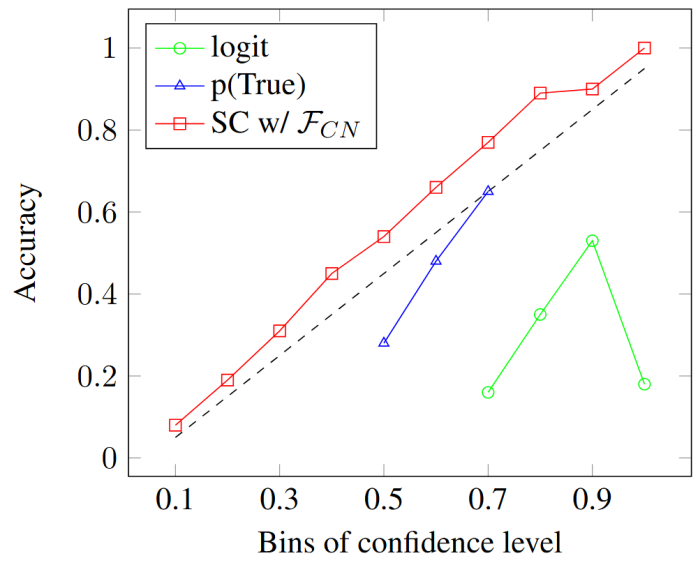
Calibration研究模型预测置信度与真实准确率之间的对齐程度,有助于衡量模型的可靠性。该工作研究大语言模型在数学推理问题上的Calibration。实验表明,传统基于概率的评价方法在该场景下表现欠佳,此外,当前广泛使用的商业大模型产品往往难以获取预测概率。对此,该工作提出基于一致性的置信度方法,根据多次采样的答案聚类结果,设计了三种计算置信度的方式:(1)基于类别数;(2)基于类内样本数;(3)基于类别间样本数。多个数据集、不同大模型上的实验表明,三种方法均显著优于传统基于预测概率的方法。






