近日,自然语言处理国际会议 ACL 2024 公布录用结果。我中心语言数据知识计算课题组有6篇论文被录用。ACL 是自然语言处理领域最受关注的国际学术会议之一,在CCF学术推荐列表中被认定为A类会议。ACL 2024 将于2024年8月11日至16日在泰国曼谷召开。此次被录用的论文的相关信息如下:
论文 1. Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal (main, long paper)
论文第一作者是我中心22级硕士生黄健亨,通讯作者是苏劲松教授,由崔乐阳(腾讯),22级博士生王安特,杨成义(哈理工),宋林峰(腾讯西雅图)和姚俊峰教授等合作完成。
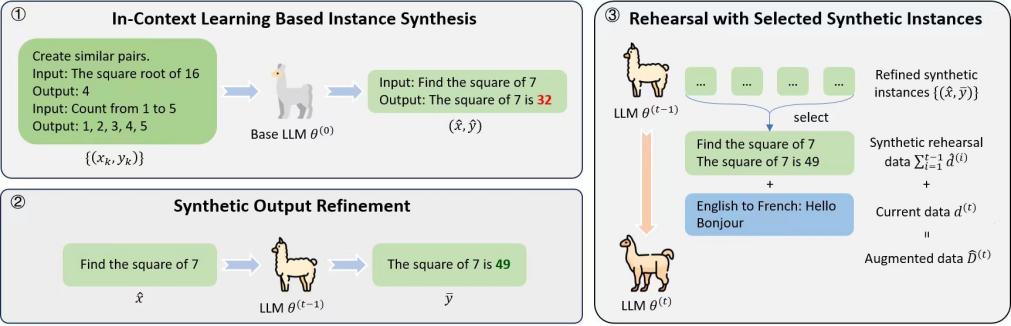
大语言模型在持续学习阶段存在灾难性遗忘问题。传统的基于回顾(rehearsal)的方法依赖历史训练数据维持模型能力,但这类方法难以应对原始训练数据不易获取的问题。 针对该问题,文章提出了一种称为自我合成回顾的大语言模型训练框架,使用大语言模型自身合成训练数据,包含以下三个步骤:1)基于上下文学习的实例合成:给定少量示例,使用基座大语言模型合成实例。2)合成实例输出求精:给定上一步得到的合成实例的输入部分,使用最新大语言模型重新生成合成实例的输出部分,保持其当前已获得的能力。3)选取合成实例回顾训练:挑选高质量的合成实例用于大语言模型后续阶段的训练。实验结果表明,我们框架相比传统的基于回顾的方法性能更优或可比,同时在数据利用方面更高效,可有效保持大语言模型通用领域的泛化能力。
论文 2. Retaining Key Information under High Compression Rates: Query-Guided Compressor for LLMs (main, long paper)
论文共同第一作者是我中心21级硕士生曹志伟和字节火山翻译曹骞研究员,共同通讯作者是程善伯研究员(字节)和苏劲松教授,由卢宇(字节)等合作完成。
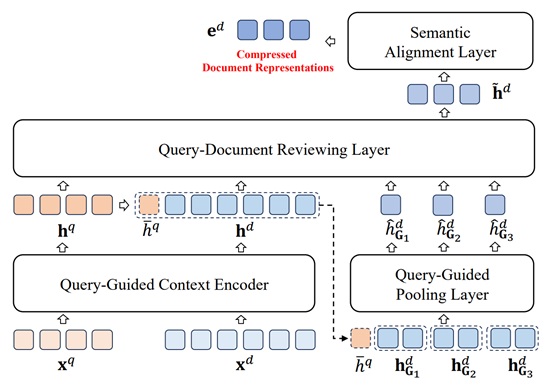
大语言模型的日益普及引发了人们对大语言模型上下文压缩的兴趣。然而,先前方法的性能随着压缩率的增加而急剧下降,有时甚至降至闭卷水平。这种下降可以归因于上下文在压缩过程中丢失了关键信息。文章的初步研究支持了这一假设,并强调了在高压缩率下保留关键信息以维持模型性能的重要性。因此,文章提出了查询引导压缩器(QGC),利用查询来指导上下文压缩过程,以有效地在压缩时保留上下文中的关键信息。此外,文章采用了动态压缩策略实现了更高的压缩比。在知识问答和少样本学习两个任务上的实验结果表明,QGC 在高压缩率下仍能保持良好的性能,同时在推理成本和吞吐量方面也具有显著优势。
论文 3. Improving LLM Generations via Fine-Grained Self-Endorsement (findings, long paper)
论文第一作者是我中心22级博士生王安特,共同通讯作者是宋林峰研究员(腾讯西雅图)和苏劲松教授。
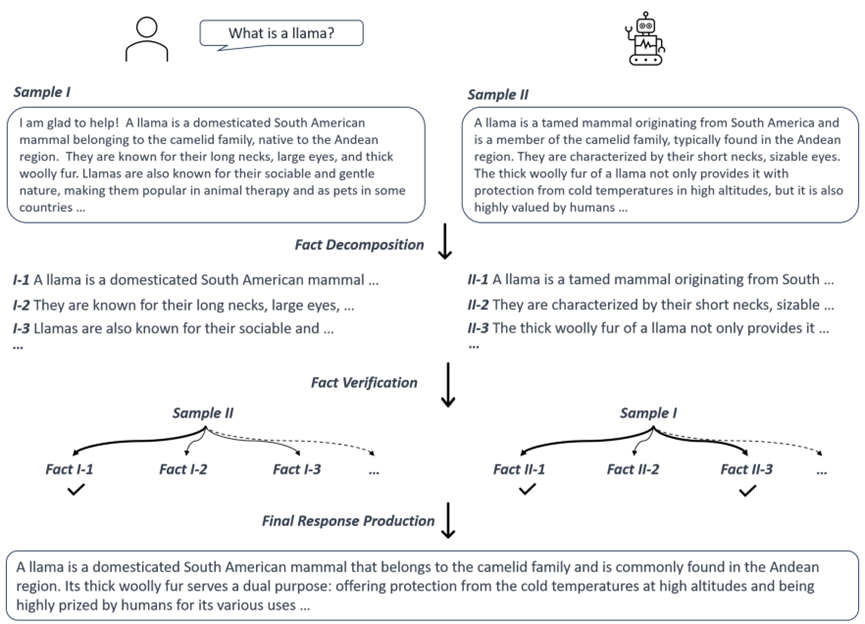
知识幻觉问题指模型预测结果对输入指令忠实度低,或包含与世界常识冲突的事实性错误,是大语言模型面临的重要挑战之一。本文提出 self-endorsement 的推理框架,在模型推理阶段减少文本中的事实性错误或推理错误,从而缓解幻觉现象。Self-endorsement 首先基于采样的方式,根据采样结果间的细粒度事实一致性,识别模型置信度低,存在幻觉可能性高的事实;之后,通过挑选低幻觉程度的采样结果,或收集高质量知识重新生成的方式,获取最终的模型回复。本文在长文本生成、短文本生成以及数学推理任务上验证 self-endorsement 框架的有效性,结果表明,self-endorsement 能够有效降低回复中的事实或推理错误,从而提高最终回复质量。
论文 4. Translatotron-V(ison): An End-to-End Model for In-Image Machine Translation (findings, long paper)
论文第一作者是我中心22级硕士生蓝志彬,通讯作者是苏劲松教授,由牛力强(微信),孟凡东(微信),周杰(微信)和张民教授(哈工大)等合作完成。
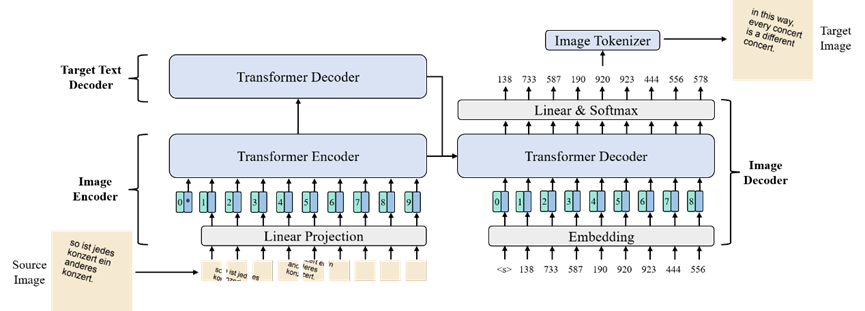
该研究聚焦于端到端图像内机器翻译任务。图像内机器翻译旨在将包含源语言文本的图像翻译为包含目标语言文本的图像。传统的级联方法串联 OCR 模型,机器翻译模型以及文生图模完成任务,存在误差传播、参数庞大、部署和保留输入图像的视觉特征困难等问题。然而,端到端模型面临两个主要挑战:1)巨大的建模负担,其需要同时学习跨语言对齐并保留输入图像的视觉特征;2)直接预测过长的像素序列较为困难。针对这些问题,文章提出了一个端到端模型 Translatotron-V,其包含图像编码器,目标文本解码器,图像解码器以及图像分词器。其中,目标文本解码器用于减轻语言对齐负担,图像分词器将长像素序列转换为较短的视觉 token 序列,防止模型过度专注于低级的视觉特征。此外,文章为该模型设计了一个两阶段的训练框架,以帮助模型学习跨模态和跨语言的表示。最后,文章还提出了一种名为 Structure-BLEU 的位置感知评估指标来评估生成图像的翻译质量。实验结果表明,Translatotron-V 只需要级联模型70.9%的参数就达到了和其相当的性能,并且显着优于像素级的端到端图像内机器翻译模型。
论文 5. Towards Better Graph-based Cross-document Relation Extraction via Non-bridge Entity Enhancement and Prediction Debiasing (findings, long paper)
论文第一作者是我中心22级硕士生岳皓,通讯作者是苏劲松教授,由赖少鹏(阿里通义),杨成义(哈理工),23级博士生张亮和姚俊峰教授等合作完成。
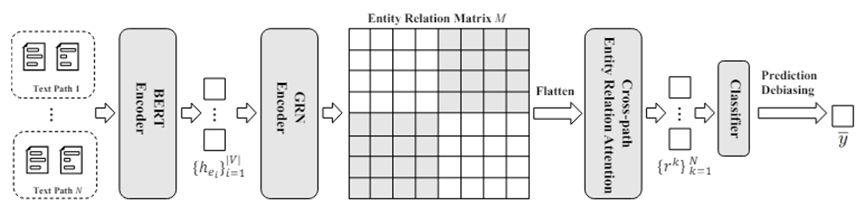
该研究聚焦于跨文档关系抽取任务。跨文档关系抽取旨在判断不在同一文档共现的目标实体对之间存在何种关系。目前该研究领域存在两个问题:1)只考虑了桥接实体和目标实体对,忽略了非桥接实体。2)数据集中无关系的数据过多,导致模型在推理阶段存在预测偏置。针对上述问题,该文章首先引入非桥接实体,并通过图网络建模非桥接实体,桥接实体以及目标实体对之间的关系。其次,文章提出了一种新颖的去偏策略来校准原始模型的预测分布。 实验结果表明,该文章提出的模型在当前任务所有的数据集上优于现有模型。
论文 6. Efficient k-Nearest-Neighbor Machine Translation with Dynamic Retrieval (findings, long paper)
论文共同第一作者是我中心24级硕士生高言和21级硕士生曹志伟,通讯作者是苏劲松教授,由21级硕士生缪忠剑,24级硕士生刘诗雨,杨宝嵩(阿里通义)和张民教授(哈工大)等合作完成。
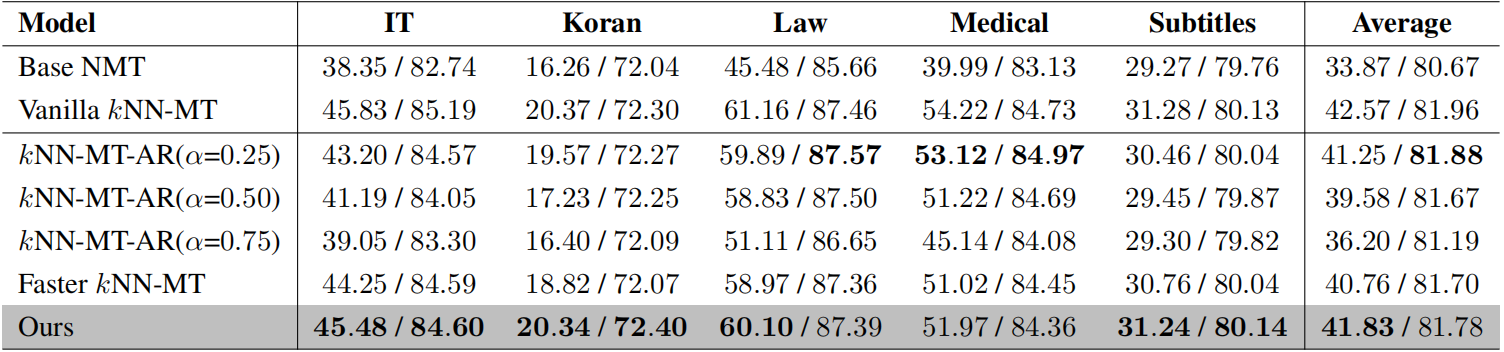
该研究聚焦于 k 近邻机器翻译(kNN-MT)任务。kNN-MT 通过构建外部数据库以存储特定领域的翻译知识,并在神经机器翻译模型每个解码时间步对外部数据库进行 k 近邻检索以改进翻译结果,从而实现了非参数化的领域自适应。然而,每个解码时间步都进行k近邻检索导致了大量时间开销,严重影响了 kNN-MT 的可用性和实用性。针对此问题,文章首先分析了以往研究提出的带自适应检索的 kNN-MT,揭示了其两个关键局限性:1)优化目标的差距导致对于判断是否跳过 kNN 检索的 λ 估计不准确,2)使用固定阈值不能满足不同解码时间步对 kNN 检索的动态需求。为了缓解这些局限性,文章提出了带动态检索的 kNN-MT,在两个方面扩展了 kNN-MT。具体地说,文章为 kNN-MT 配备了基于MLP的分类器,用于判断每个解码时间步是否跳过 kNN 检索,并提出了一种时间步感知的动态阈值方法。大量实验和分析有力地证明了文章提出的方法的有效性。






