近日,计算机图形学与多媒体国际会议ICME 2024公布录用结果,我中心4篇论文被录用。ICME会议全称为IEEE International Conference on Multimedia & Expo,在CCF学术推荐列表中被认定为B类会议。
此次被录用的论文的相关信息如下:
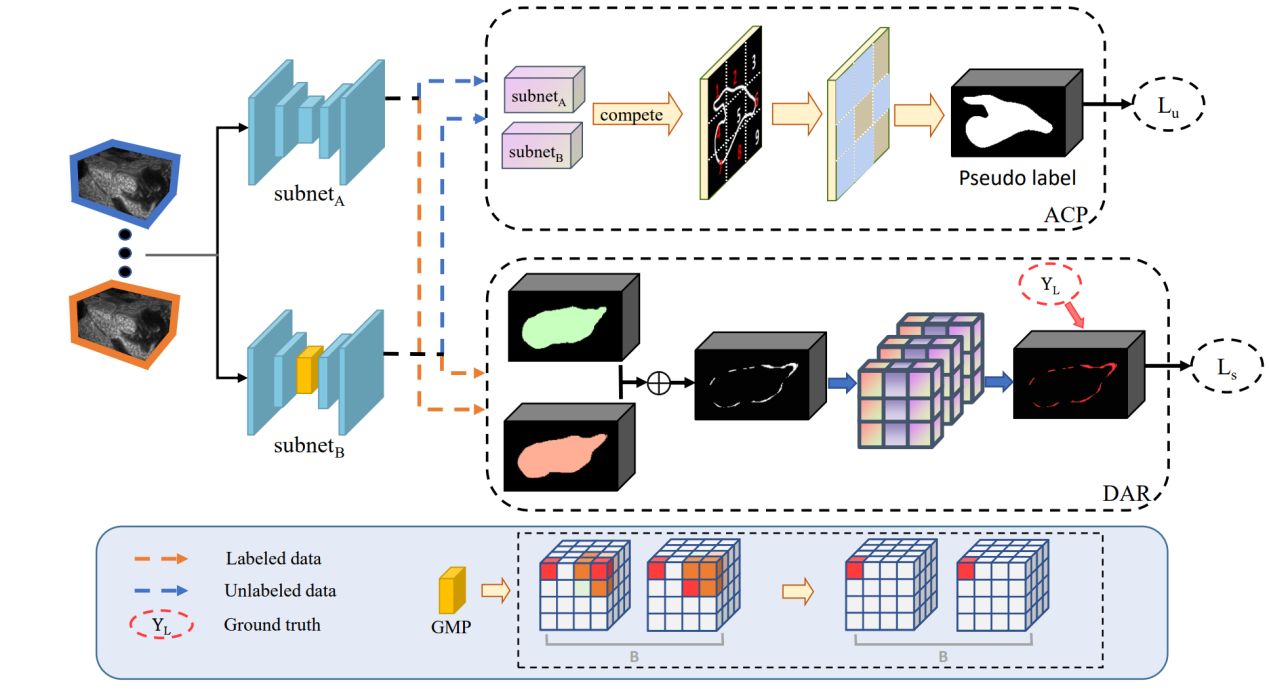
题目:DPP-Net: Difficulty Perception-Processing Heterogeneous Network for Semi-supervised Medical Image Segmentation(作者:Qiqin Lin, Weixing Xie, Rongzhou Zhou, Xianpeng Cao, Jingze Chen, Junfeng Yao, Qingqi Hong)。本文由我中心2022级硕士生林祺钦,姚俊峰教授,洪清启副教授合作完成。
在半监督医学图像分割中,标记数据的稀缺性使得模型容易陷入学习偏差,导致某些区域持续出现错误,最终导致过拟合,严重影响了分割性能。这些问题区域被称为困难区域,现有方法对其处理乏力。为此,我们提出了困难感知-处理异构网络(DPP-Net)。它指导模型准确感知和修正困难区域,克服学习偏差。具体来说,我们引入了全局相互感知(GMP),在样本数据之间建立了全面的信息感知通道,实现了对困难区域的更全面和准确的感知。困难感知-修正(DAR)结构确保在训练过程中持续监测困难区域,指导模型及时调整错误。此外,自适应竞争伪标签(ACP)增强策略通过自适应置信度竞争增强了伪标签。在两个不同的医学图像数据库(CT和MRI)上的实验结果表明,我们的方法优于最先进的方法。
该研究工作得到了国家自然科学基金项目(No.62072388)、厦门市公共技术服务平台项目(No.3502Z20231043)、福建省阳光慈善公益基金会的支持。
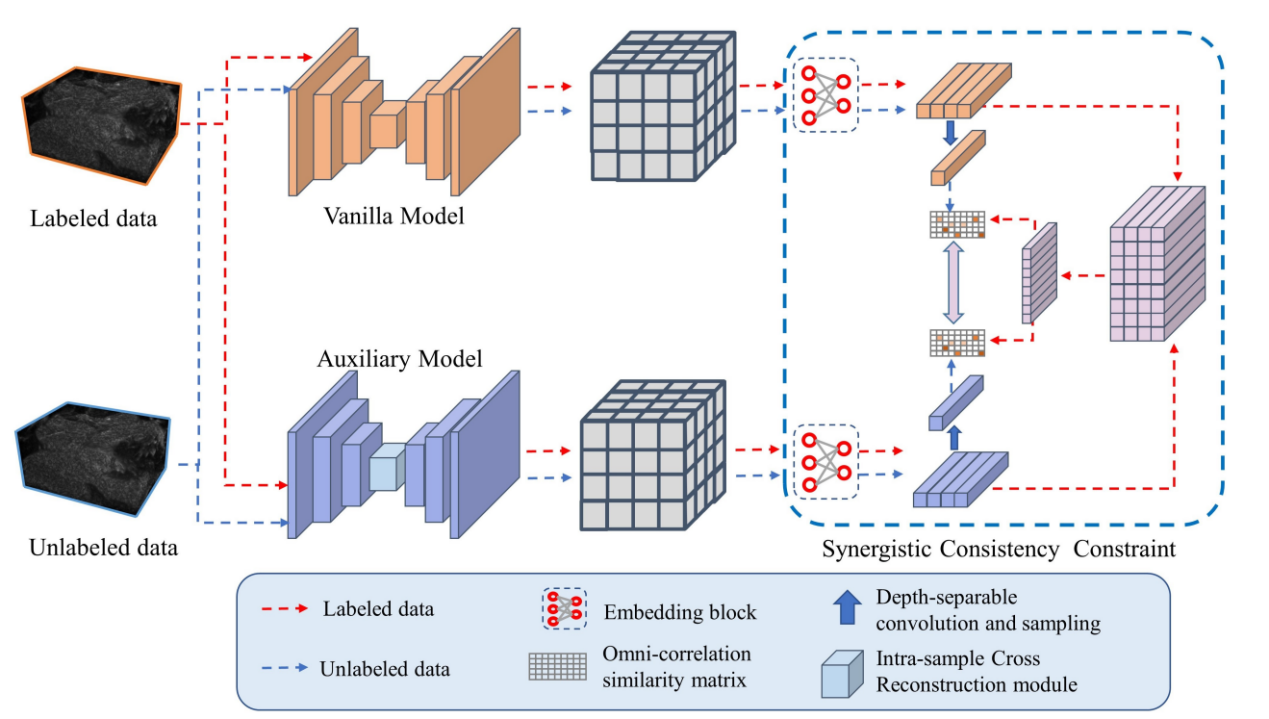
题目:ICR-Net: semi-supervised medical image segmentation guided by intra-sample cross reconstruction(作者:Xianpeng Cao, Weixing Xie, Rongzhou Zhou, Qiqin Lin, Junfeng Yao, Qingqi Hong)。本文由我中心2022级硕士生曹贤鹏,姚俊峰教授,洪清启副教授合作完成。
半监督学习在医学影像分割领域越来越受欢迎,因为它能利用大量无标记数据提取额外信息。然而,大多数现有的半监督分割方法只关注从无标签数据中提取信息,而忽略了标签数据进一步提高模型性能的潜力。在本文中,我们提出了一种新的样本内交叉重建网络(ICR-Net)框架,利用标记数据帮助网络从无标记数据中提取信息,从而指导网络的正则化学习。我们的方法包含两个模块: ICR模块以更精细的方式处理标记数据特征,从而使网络能够更有效地学习和捕捉输入中的关键模式和特征,而SCC则通过制定额外的模型正则化来指导网络的正则化学习。在LA数据集和Pancreas数据集上的实验表明,在医学图像分割任务中,我们提出的框架比目前最先进的方法更有效。
该研究工作得到了国家自然科学基金项目(No.62072388)、厦门市公共技术服务平台项目(No.3502Z20231043)、福建省阳光慈善公益基金会的支持。
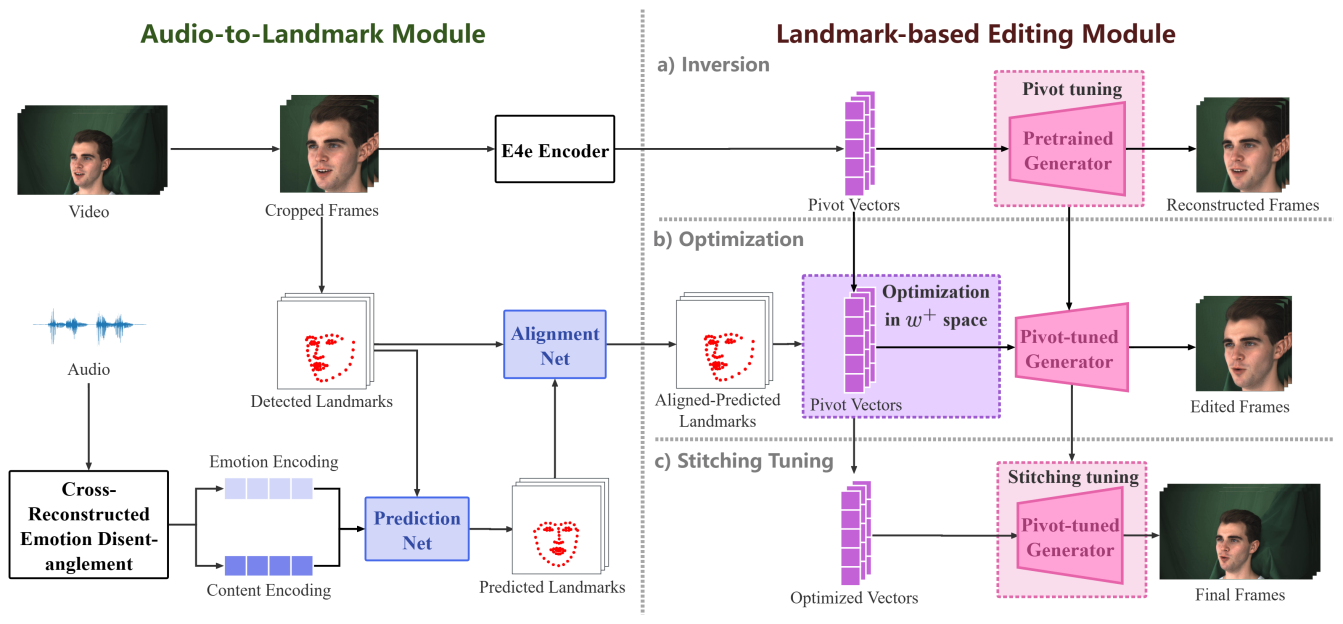
题目:Audio-driven High-resolution Seamless Talking Head Video Editing via StyleGAN(作者:Jiacheng Su, Kunhong Liu, Liyan Chen, Junfeng Yao, Qingsong Liu, Dongdong Lv)。本文由我中心2022级硕士生苏嘉承,刘昆宏教授,陈俐燕副教授,姚俊峰教授合作完成。
音频驱动的说话人视频编辑是人工智能内容生成(AIGC)领域中的一个重要研究课题,旨在根据输入的音频生成与之唇形匹配的高质量说话人视频。然而,大多数现有的方法在视频质量和视频自然程度上都有所欠缺。在本文中,我们提出了一种基于StyleGAN模型的高质量说话人视频编辑框架,它能实现生成高分辨率、高质量的编辑视频。我们设计了一种新的优化方法在标注点的监督下编辑面部表情,并且融合了枢轴调优(Pivot tuning)和缝合调优(Stitching tuning)使高分辨率视频的编辑效果真实自然。此外,为了更进一步提高说话人的自然程度,我们引入情感交叉解耦重建模块对音频中的情感建模并表现在人脸编辑中。在MEAD和HDTF两个说话人视频数据集上的实验结果表明,我们的方法优于最先进的方法。该研究工作得到了厦门市公共技术服务平台项目(No.3502Z20231043)的支持。
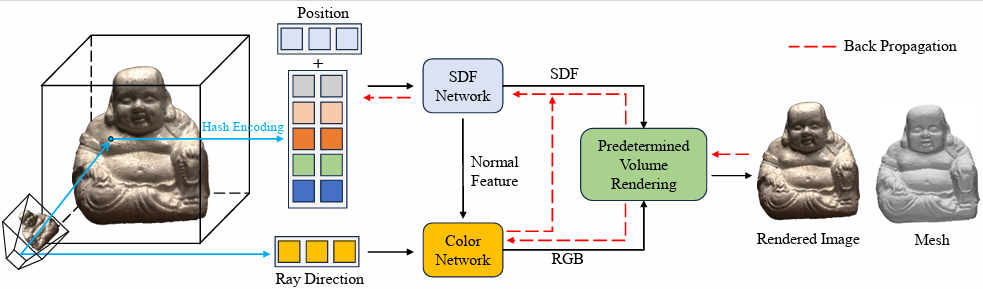
题目:FFNSR: Fast and Fine Neural Surface Reconstruction。(作者:Chuanfeng Yang, Kaiheng Li, Jiahui Chen, Qingqi Hong)。本文由我中心2022级硕士生杨传峰,洪清启副教授合作完成。
最近的神经表面表示和重建方法显示了重建表面的能力,但需要长时间的训练。最新的方法采用哈希编码来加速训练,但忽略了重建的准确性,导致表面质量下降。为了解决这个问题,我们提出了一种名为 FFnsr 的快速神经曲面重建方法,该方法包含两个优化点。首先,FFnsr 使用一个预定的线性增长函数来取代以往体渲染方法中的可学习参数。这样,网络就能在初始阶段专注于粗糙形状,并在后期阶段完善细节。同时,FFnsr 提出了一种正则化方案,使用梯度方向上的二阶导数,可以稳定网络的训练并获得更平整的表面。我们在 DTU 数据集上的实验结果表明,FFnsr 可以生成高质量、稳健的重建结果,同时保持较快的速度。
该研究工作得到了厦门黑镜科技有限公司的支持。