近日,人工智能国际会议AAAI 2024公布录用结果,我中心语言数据知识计算课题组2篇论文被录用。AAAI会议全称为Annual AAAI Conference on Artificial Intelligence,由国际先进人工智能协会(Association for the Advancement of Artificial Intelligence, AAAI)举办,是人工智能领域最重要的学术会议之一,在CCF学术推荐列表中被认定为A类会议。
录用论文的相关信息如下:
题目:Response Enhanced Semi-Supervised Dialogue Query Generation(作者:Jianheng Huang, Ante Wang, Linfeng Gao, Linfeng Song, Jinsong Su)。本文由我中心2022级硕士生黄健亨同学,2022级博士生王安特同学,2020级本科生高琳峰同学,苏劲松教授(通讯作者)和腾讯AI Lab西雅图实验室高级研究员宋林峰合作完成。
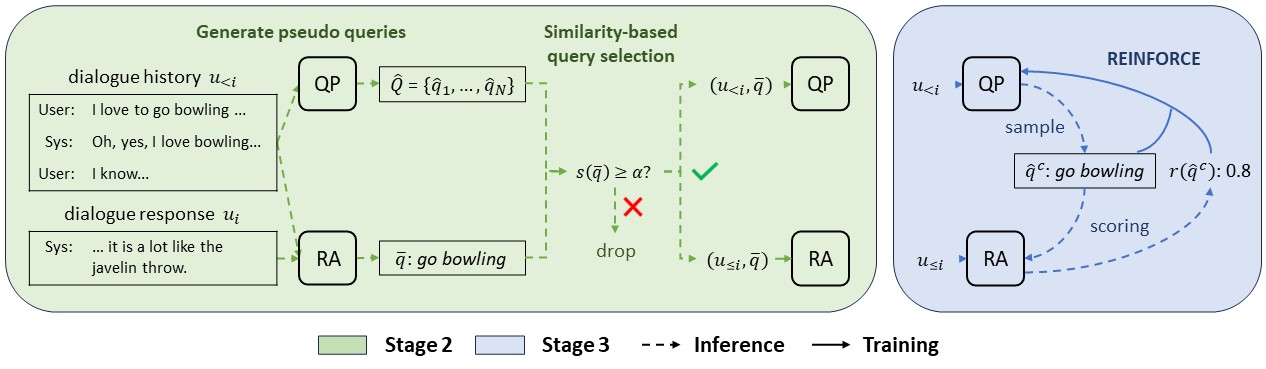
本工作聚焦半监督对话查询生成任务,其中对话查询生成基于对话历史生成搜索查询,有助于模型检索和获取外部知识。而现有的对话查询生成工作主要关注标注数据收集和模型监督训练,存在数据稀缺和领域适应的问题。研究表明,引入对话回复作为额外输入,模型预测性能往往更佳,这可用于生成伪查询参与半监督训练。但模型有时会过度依赖回复信息,从而产生一些低质量的伪查询。鉴于上述问题,本工作首次提出一种三阶段的半监督对话查询生成训练框架SemiDQG。在阶段1,本工作使用标注数据训练标准查询生成器(QP)和回复增强查询生成器(RA)。在阶段2,本工作使用QP和RA为无标注数据生成伪查询,基于相似度挑选RA生成的高质量伪查询来构造伪实例,用于训练QP和RA。在阶段3,本工作引入强化学习,利用RA为QP采样得到的候选查询打分,从而为QP提供细粒度的训练信号,进一步训练QP。本工作在中英文三个基准数据集上进行实验,充分分析讨论了SemiDQG在跨领域和低资源场景上的表现,证明了训练框架的有效性。
题目:Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment(作者:Rui Zhao, Liang Zhang, Biao Fu, Cong Hu, Jinsong Su, and Yidong Chen)。本文由厦门大学自然语言处理实验室陈毅东老师团队和我中心2023级博士生张亮同学,苏劲松教授合作完成。

本工作研究手语翻译(Sign Language Translation, SLT)中的模态对齐问题。现有的手语翻译主要借鉴神经机器翻译的方法,然而不同于普通的机器翻译任务,手语翻译任务接收视觉模态的手语视频作为输入,并且输出文本模态的目标句子。这种模态之间的差异限制现有手语翻译模型的性能。为了缓解这个问题,本文提出一种基于条件变分自编码器(Conditional Variational Autoencoder,CVAE)的手语翻译框架CV-SLT。该框架包含两条路径:先验路径和后验路径。在先验路径中,模型只依赖视觉信息预测目标文本。在后验路径中,模型同时编码视觉信息和文本信息来重构目标文本。与此同时,本工作使用了两个KL散度来对齐encoder与decoder的输出。本文在PHOENIX14T和CSL-Daily两个数据集上验证了模型的有效性,并通过消融实验证明了提出的框架可以促进模态对齐。






