近日,我中心语言数据知识计算课题组6篇论文被权威会议EMNLP2023和权威期刊IEEE/ACM-TASLP期刊录用。EMNLP会议全称为Conference on Empirical Methods in Natural Language Processing,由国际计算语言学协会ACL举办,是自然语言处理和人工智能领域最重要的学术会议之一,在CCF学术推荐列表中认定为B类会议,清华计算机学术推荐列表中认定为A类会议。TASLP期刊全称为IEEE/ACM Transactions on Audio, Speech and Language Processing,是音频、声学、语言信号处理的权威期刊,在CCF学术推荐列表中认定为B类刊物,清华计算机学术推荐列表中认定为A类刊物。录用论文的相关信息如下:
论文1. 题目:Exploring All-In-One Knowledge Distillation Framework for Neural Machine Translation(作者:Zhongjian Miao, Wen Zhang, Jinsong Su, Xiang Li, Jian Luan, Yidong Chen, Bin Wang and Min Zhang;收录情况:EMNLP2023主会长文)本文由我中心2021级硕士生缪忠剑同学、苏劲松老师(共同通讯作者)、陈毅东老师(共同通讯作者)和小米AI实验室张文研究员、李响研究员等合作完成。
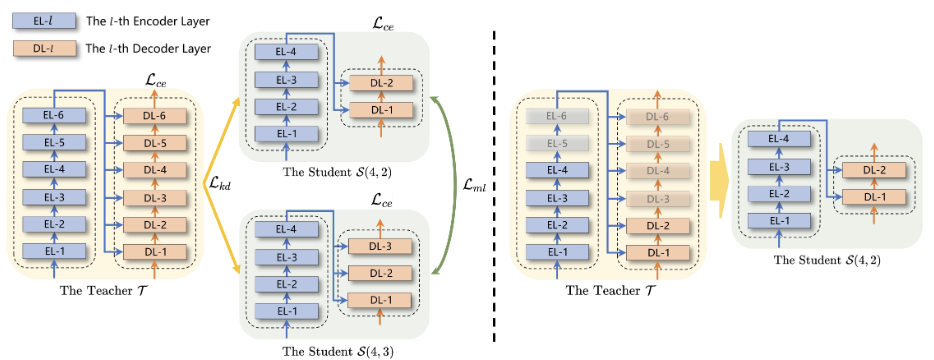
传统的知识蒸馏方法在需要蒸馏多个不同的学生模型的场景下开销巨大。针对该问题,文章提出一种高效的面向多学生场景的知识蒸馏框架。在该框架下,学生模型为教师模型的若干子结构并与教师模型联合训练,其中,学生模型与教师模型之间进行知识蒸馏训练,学生模型之间进行互学习训练。在多个机器翻译的数据集上的实验表明,与传统的知识蒸馏方法相比,该框架能够在低得多的训练开销下获得质量更优的学生模型,深入的分析实验也证实了该框架中各个部件的有效性。
论文2. 题目:IBADR: an Iterative Bias-Aware Dataset Refinement Framework for Debiasing NLU models (作者:Xiaoyue Wang,Xin Liu, Lijie Wang,Yaoxiang Wang,Jinsong Su,Hua Wu; 收录情况:EMNLP2023主会长文)。本文由我中心2021级博士生王笑月同学、2023级硕士生王耀祥同学、苏劲松老师(通讯作者)和百度王丽杰研究员等合作完成。
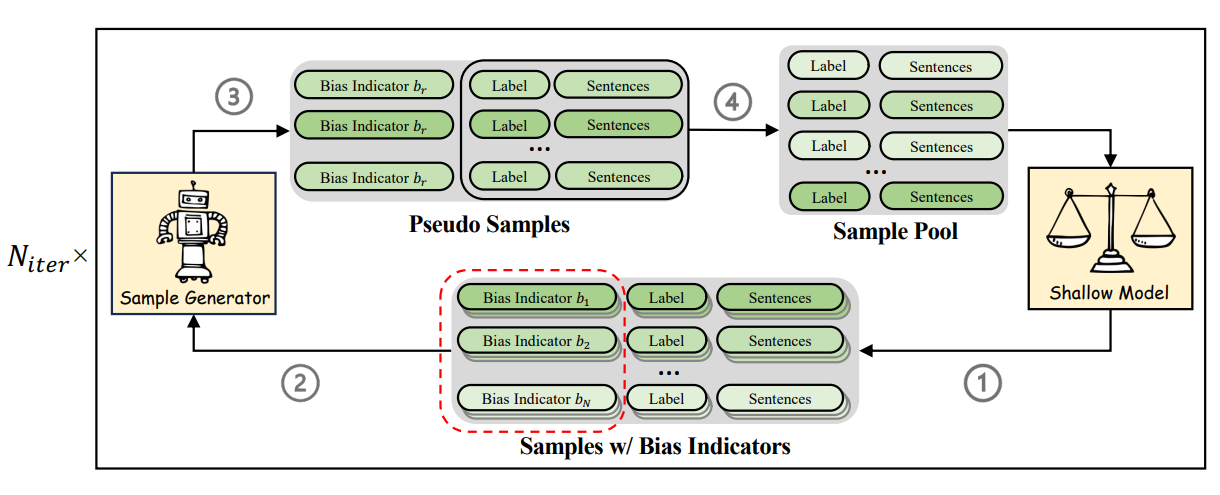
该研究聚焦于自然语言理解任务中的偏置问题。现有的数据集修正工作大多需要事先定义偏置特征,因此需要耗费大量人力资源,且模型泛化性低。针对上述问题,本研究提出一个偏置特征自感知的迭代式数据集修正框架。该框架分为4步:1.通过训练一个弱模型来评估每条样本的偏置程度,并分配对应的偏置指示器;2.使用上述样本训练生成器,在每一轮训练后指定一个偏置指示器要求模型生成一批数据扩充训练集;3.针对扩充后的训练集重新评估偏置程度,训练生成器;4.重复上述3个步骤,直到达到最大迭代次数为止。多方面的实验证明了该框架所生成的增强数据在缓解自然语言理解任务偏置问题上的有效性。
论文3. 题目:HyperNetwork-based Decoupling to Improve Model Generalization for Few-Shot Relation Extraction(作者:Liang Zhang, Chulun Zhou, Fandong Meng, Jinsong Su, Yidong Chen, Jie Zhou;收录情况:EMNLP2023主会长文)。本文由我中心2023级博士生张亮同学、苏劲松老师(共同通讯作者)、陈毅东老师(共同通讯作者)和微信周楚伦研究员、孟凡东研究员等合作完成。
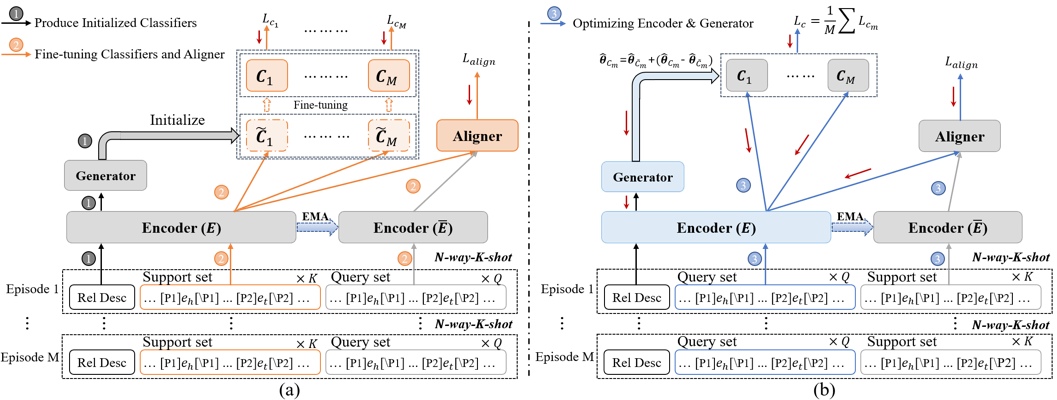
该研究聚焦于Few-shot关系抽取(Few-shot RE)任务,该任务旨在增强RE模型对新关系的泛化性。现有的研究主要使用原型网络来解决该问题。然而,这些基于原型网络的方法依然存在对训练集中关系过拟合的风险,这也严重地限制了RE模型对新关系的泛化性。针对该问题,文章提出了一个基于超网的解藕方法来解决RE模型对训练集中关系的过拟合问题。具体来说,文章首引入了一个基于超网的生成器,其能够显示地将模型解藕为下层的编码器和上层的分类器。同时,文章进一步提出了一个两阶段的训练策略,其使得下层的编码器聚焦于学习关系通用的知识同而上层的分类器聚焦于学习关系特定的知识。特别地,在推理过程中该生成器能够基于下层的编码器为新关系生成特定的上层分类器。这种方式有效地避免了训练集中关系特定知识对RE模型泛化性的影响。广泛的实验和深入的分析有力地证明了该文章提出的方法和训练策略的有效性。
论文4. 题目:Domain Adaptation for Conversational Query Production with the RAG Model Feedback (作者: Ante Wang, Linfeng Song, Ge Xu, and Jinsong Su;收录情况:EMNLP2023 Findings长文)。本文由我中心2022级博士生王安特,苏劲松教授(通讯作者),腾讯西雅图AI Lab高级研究员宋林峰等合作完成。
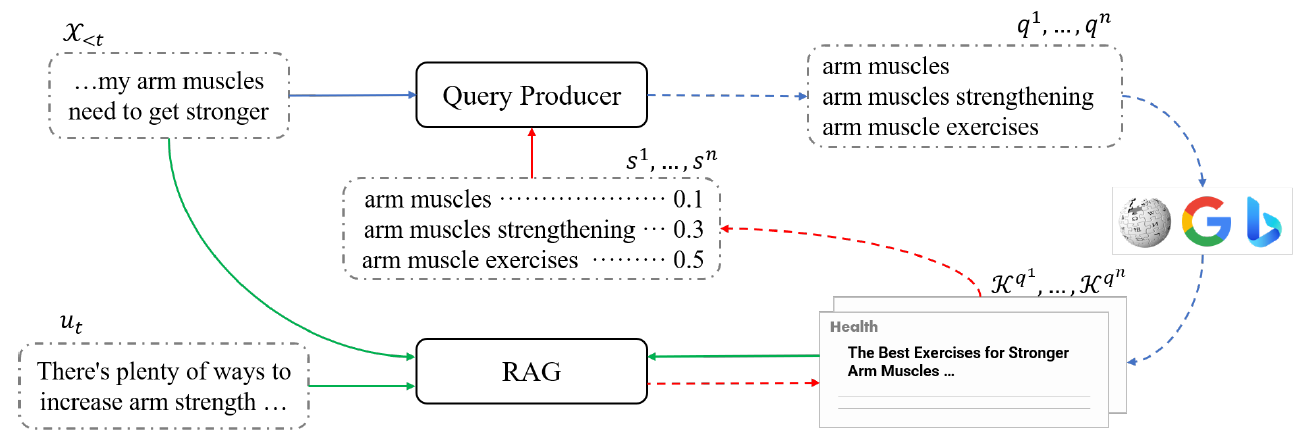
本工作关注基于搜索引擎检索知识增强的对话系统,特别是检索查询生成的关键模块研究。在现有的有监督以及弱监督的工作基础上,进一步结合两者的优势,首次将研究方向拓展到领域迁移的半监督学习场景。特别地,由于真实场景搜索引擎检索结果以及对话数据中存在大量的无关噪声,现有方案受限于以文本匹配的方式获取目标领域数据上弱监督信号供模型训练,故无法有效挖掘深度语义信息提供更好的训练信号,限制了模型的效果。如下图所示,本工作提出通过引入额外的知识增强对话回复模型(RAG),根据当前查询模型生成的结果的检索知识,其结果以强化学习的方式反馈给查询模型。通过使用RAG模型充分挖掘深度语义信息,避免了噪声对训练查询生成模型的干扰。本工作构建了干净数据集和噪声数据集进行实验,结果表明在噪声数据集上,提出的方法能显著提升模型性能,验证了方法有效性。
论文5. 题目:Continual Learning for Multilingual Neural Machine Translation via Dual Importance-based Model Division(作者:Junpeng Liu, Kaiyu Huang, Hao Yu, Jiuyi Li, Jinsong Su and Degen Huang;收录情况:EMNLP2023主会长文)。本文由大连理工大学黄德根老师课题组与我中心苏劲松老师合作完成。
本文针对现有多语言翻译模型在持续学习中原有翻译任务的性能保持问题和新增翻译任务的性能提升问题,提出基于双重参数重要性的模型分割建模方法。首先,在原始多语言翻译模型M基础上对新增翻译任务进行微调得到模型N,并分别对模型M和N中的参数进行重要性评估;之后,根据评估结果对模型M进行剪枝,删除对原始翻译任务重要性较小但对新翻译任务重要性较高的参数,并将剪枝后的模型M’用于原始翻译任务;最后,利用模型N中的参数将剪枝后的模型M’扩展至原始规模,并在新增翻译任务上对新增加的参数进行微调得到模型N’,用于新增翻译任务。模型剪枝能够较好地保持原有翻译任务的性能并实现模型压缩,模型扩展和微调能够提升模型对新增翻译任务特有知识的迁移和建模能力。实验结果证明了本文方法的有效性。
论文6. 题目:D2PSG: Multi-Party Dialogue Discourse Parsing as Sequence Generation(作者:Ante Wang, Linfeng Song, Lifeng Jin, Junfeng Yao, Haitao Mi, Chen Lin, Jinsong Su and Dong Yu;收录情况:期刊IEEE/ACM Transactions on Audio, Speech, and Language Processing)
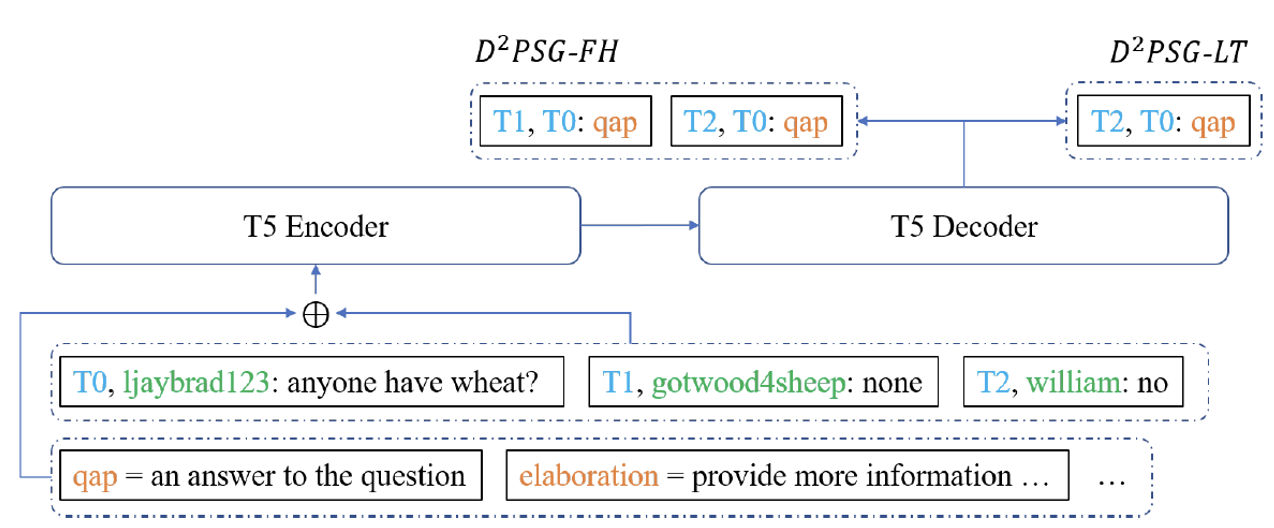
该论文由我中心2022级博士生王安特,苏劲松教授(通讯作者),腾讯西雅图AI Lab高级研究员宋林峰等合作完成。本工作研究多人对话篇章解析任务,分析表明尽管现有的模型基于预训练模型微调,却无法通过增大预训练模型参数量提升性能,其原因在于现有方法均需要引入了额外的分类头或篇章级编码器,在训练数据有限的条件下,这部分随机初始化参数难以适配更大预训练模型的丰富输出表示,造成“增量诅咒”的现象。本工作首次提出将该任务建模为文本到文本生成的任务,仅通过预训练模型即可完成预测,从而避免了额外参数的引入。此外,本工作进一步引入了标签描述信息,使模型更充分理解不同关系标签的语义,减少对数据量的需求。本工作在两个标准基线上进行实验,并充分分析讨论了该方法在低资源、跨领域、长尾标签分布上的表现,证明了方法的有效性。






