近日,厦门大学信息学院苏劲松教授课题组,腾讯微信模式识别中心等单位在国际计算机学术期刊Artificial Intelligence(CCF-A类期刊)合作发表了题为”Multi-modal Graph Contrastive Encoding for Neural Machine Translation”的最新研究成果。
与仅使用文本的机器翻译模型不同,多模态机器翻译模型不仅要建模文本的语义表达,还要充分利用对应的视觉模态信息作为文本语义的补充,从而达到更准确的翻译性能。影响该模型的关键因素是多模态语义的建模和融合方法,这也是该研究领域的研究重点。
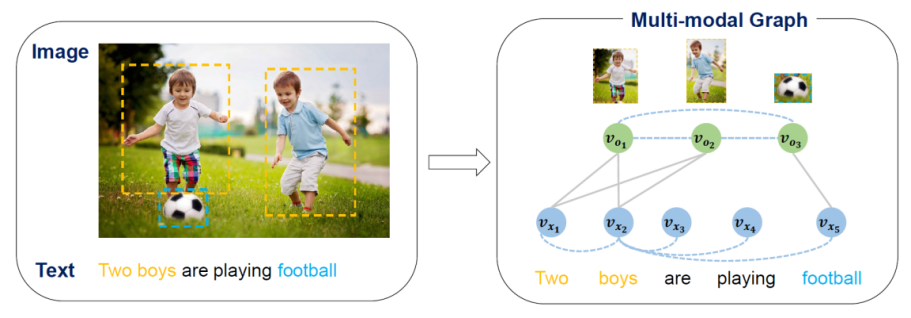
图1. 文本图片对的多模态图表示
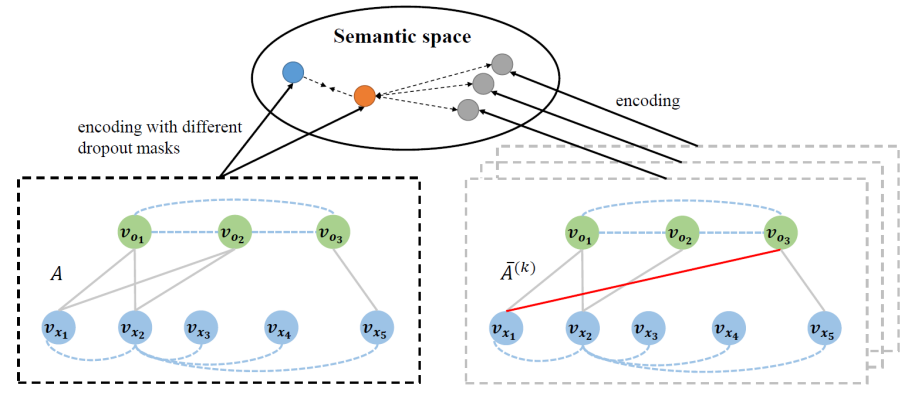
图2. 基于多模态图的对比学习
针对这个问题,如图1所示,本研究提出一种统一的多模态图来建模输入的文本和图片对,将两种模态中的语义单元(图片中的物体和文本中的词)建模为图结构中的节点。对于同模态的节点,采用全连接的图结构;对于跨模态的节点,则采用视觉定位工具来建立跨模态语义连边。基于此多模态图结构,使用图神经网络的特征融合层迭代地进行模态内和模态间的信息传播和融合,用于学习图结点的语义表示,解码器仅需要关注文本模态节点生成译文。此部分研究发表在自然语言处理国际会议ACL2020。为了充分利用多模态训练实例,本研究进一步引入了渐进式对比学习策略来增强多模态图表示学习。如图2所示,对于每个训练实例,正样本为输入多模态图结构经过dropout扰动的表示。负样本包括随机选择的负样本,即同一批次中的其他多模态图,以及困难的负样本,通过破坏图的跨模态对齐或视觉特征构建而成。通过训练模型拉近表示空间中的实例和正样本,同时将其与负样本区分开来。为了获得更平滑的训练过程,在训练中逐渐增加困难负样本的数量,以一种由易到难的方式有效地完善模型训练。在Multi30K数据集上的实验结果和深入分析验证了本研究提出模型和方法的有效性。
该项工作由我中心2020届硕士生尹永竞同学(现西湖大学博士生),曾嘉莉同学(共同一作,现腾讯微信模式识别中心研究员),苏劲松教授(通讯作者)、周楚伦同学、孟凡东研究员(微信)、周杰总监(微信)、黄德根教授(大连理工)、罗杰波教授(罗切斯特大学)合作完成。
该工作得到了科技创新2030--新一代人工智能重大项目(2020AAA0108004)、国家自然科学基金 (62276219)、福建省杰出青年基金(2020J06001)等项目的资助。
论文链接:https://authors.elsevier.com/sd/article/S0004-3702(23)00132-7






