近日,计算机多媒体国际会议ACM MM 2023公布录用结果。我中心有2篇论文被录用。ACM MM23将于2023年10月29日至2023年11月3日在加拿大渥太华召开。此次被录用的论文的相关信息如下:
论文1. 题目:ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding。论文由我中心2022级硕士生李子晗同学、郑渊同学、单丹丹同学、洪清启副教授、罗祥德同学(电子科大)合作完成。
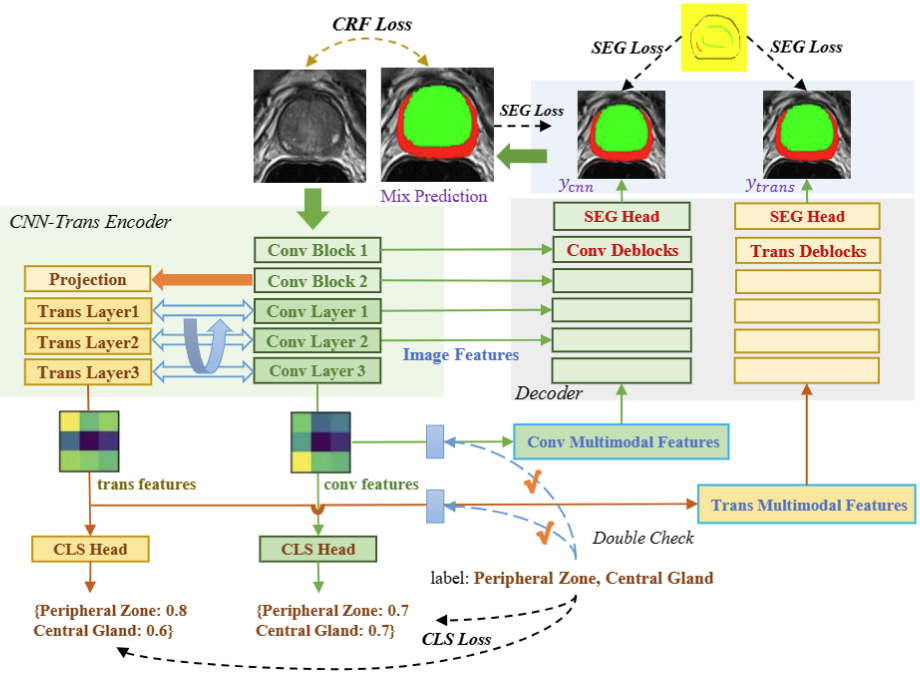
本论文提出了一种新颖的基于涂鸦监督的医学图像分割框架ScribbleVC,其利用视觉和类别嵌入的多模态信息增强机制来有效提升模型性能。此外,ScribbleVC还综合利用了CNN特征和Transformer特征,以实现更好的视觉特征提取。所提出的方法将基于涂鸦的方式与分割网络和类别嵌入模块相结合,能够生成更准确的分割mask。我们在三个基准数据集上评估了ScribbleVC,并将其与最先进的方法进行了比较。实验结果表明,我们的方法在准确性、鲁棒性和效率方面优于现有方法。
论文2. 题目:Towards Better Multi-modal Keyphrase Generation via Visual Entity Enhancement and Multi-granularity Image Noise Filtering。论文由我中心2021级硕士生董怡帆,2023级硕士生吴苏航(共同一作),孟凡东博士(微信)、周杰博士(微信)、王晓黎副教授、林剑新副教授(湖南大学)、苏劲松教授合作完成。
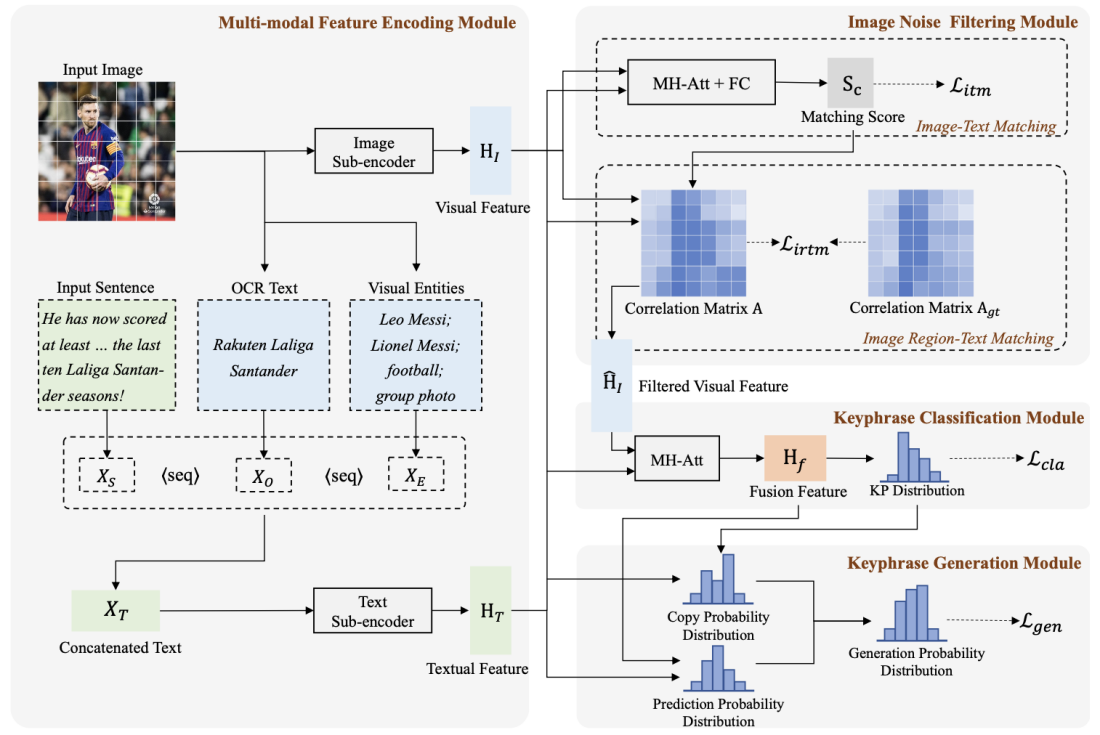
本论文针对多模态关键短语生成任务,多模态关键短语生成旨在生成一组针对输入文本-图像对的核心内容的关键短语。目前主流的方法主要通过简单的多模态融合来生成这些关键短语。然而,这些方法仍然存在两个主要缺陷:1)仅能利用有限且较为粗糙的图片信息,例如图像字幕,来提供辅助信息,但这些信息可能不足以用于后续关键短语生成。2)输入的文本和图像通常不完全匹配,导致图像可能引入噪声。为了解决这些限制,本文提出了一种新的多模态关键短语生成模型,该模型不仅用外部知识丰富了模型输入,而且有效地过滤了图像噪声。具体而言,我们首先引入图像的外部视觉实体作为模型的辅助输入,这有利于实现跨模态语义对齐。其次,我们同时计算图像-文本匹配分数和图像区域-文本相关性分数,以执行多粒度图像噪声过滤。特别是我们引入了图像区域和Ground-Truth关键短语之间的相关性分数,以优化相关性分数的计算。通过在多模态关键短语生成基准数据集上进行实验,我们证明了该方法取得了最先进的性能,并验证了本文方法的有效性。






