近日,自然语言处理国际会议ACL 2023公布录用结果。我中心语言数据知识计算课题组有6篇论文被录用。ACL是自然语言处理领域最受关注的国际学术会议之一,ACL 2023将于2023年7月9日至14日在加拿大多伦多召开。此次被录用的论文的相关信息如下:
论文1. 题目:Bridging the Domain Gaps in Context Representations for k-Nearest Neighbor Neural Machine Translation(作者:Zhiwei Cao, Baosong Yang, Huan Lin, Suhang Wu, Xiangpeng Wei, Dayiheng Liu, Jun Xie, Min Zhang and Jinsong Su;收录情况:main, long paper)。本文由我中心2021级硕士生曹志伟同学、苏劲松老师和阿里巴巴达摩院的杨宝嵩研究员、谢军研究员等合作完成。
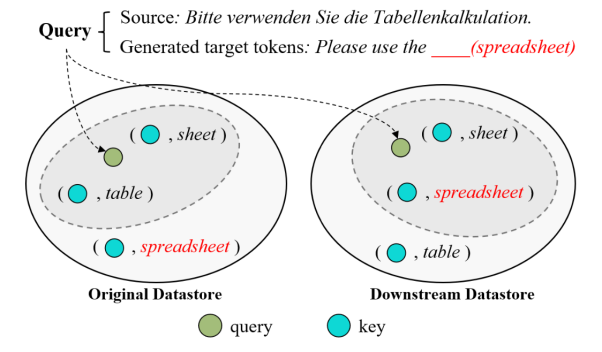
k近邻机器翻译(kNN-MT)能够非参数适应新的翻译领域。通过使用上游神经机器翻译模型遍历下游的训练语料库,该方法构建了一个包含向量化键值对的数据库,这些键值对在推理过程中被检索以提高翻译效果。然而,上下游领域之间往往存在着显著的领域差异,这将损害数据库的检索有效性和最终的翻译质量。针对该问题,文章提出了一种新的方法,通过重构原数据库来提高kNN-MT的数据库检索有效性。具体地说,文章设计了一个修订器来修正数据库中键的表示,使它们更适配于下游领域。为训练该模块,收集语义相关的键-查询对,并提出两个损失来对其进行优化:键-查询语义距离,确保每个修订后的键表示与其对应的查询在语义上是相关的;L2范数损失,鼓励修订后的键表示能有效地保留上游NMT模型所学习的知识。域适应任务上的大量实验表明,文章提出的方法可以有效地提高kNN-MT的数据库的检索有效性和最终的翻译质量。
论文2. 题目:Exploring Better Text Image Translation with Multimodal Codebook (作者: Zhibin Lan, Jiawei Yu, Xiang Li, Wen Zhang, Jian Luan, Bin Wang, Degen Huang, Jinsong Su;收录情况:main, long paper)。本文由我中心2022级硕士生蓝志彬同学,余嘉炜同学,苏劲松老师和小米AI Lab的李响研究员、张文研究员、王斌首席科学家、大连理工大学黄德根教授等合作完成。
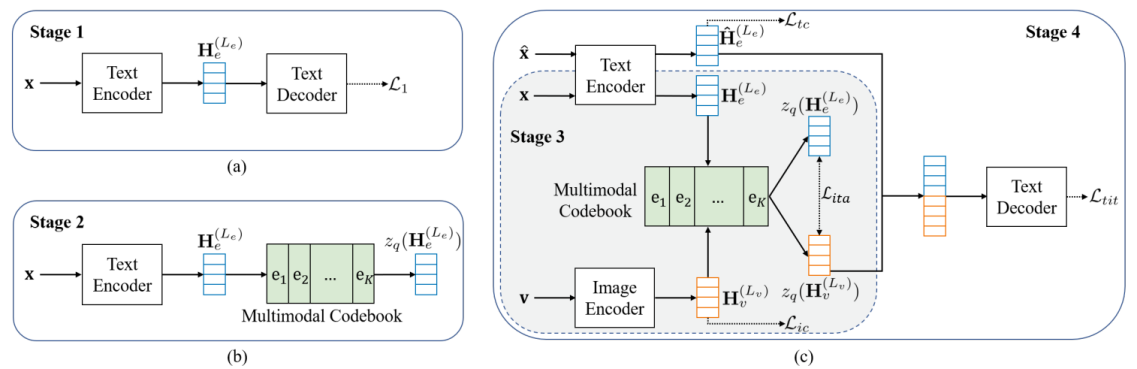
该研究聚焦于文本图像翻译任务。文本图像翻译旨在将图像中的源语言文本翻译成目标译文,目前关于文本图像翻译的研究面临两个主要瓶颈:1)缺乏公开可用的数据集,2)模型主要采用级联结构,容易受到OCR错误传播的影响。针对上述问题,首先标注了一个文本图像翻译数据集,为后续研究提供便利;其次提出了一种基于多模态码本的翻译模型,将图像与相关文本进行关联,为翻译提供有效的补充信息。此外,文章还提出了一种多阶段训练框架,充分利用了额外的双语文本、OCR数据和文本图像翻译数据。广泛的实验和深入的分析有力地证明了该文章提出的模型和训练框架的有效性。
论文3. 题目:Revisiting Non-Autoregressive Translation at Scale(作者:Zhihao Wang, Longyue Wang, Jinsong Su, Junfeng Yao and Zhaopeng Tu;收录情况:findings, long paper)。本文由中心2020级博士生王志豪同学、苏劲松老师、姚俊峰老师和腾讯AI Lab的王龙跃博士、涂兆鹏博士合作完成。
Scaling对于提高自回归翻译(AT)的译文质量至关重要,然而scaling在非自回归翻译(NAT);领域却仍然没有被系统地研究过。文章主要通过系统性地研究scaling对NAT模型行为的影响来弥补AT和NAT在研究进展上的差距。2个先进的NAT模型在6个WMT数据集上的广泛实验结果表明,scaling可以缓解NAT译文中普遍存在的问题,从而获得更好的翻译性能。为了降低scaling对NAT模型解码速度的副作用,文章分别探究scaling NAT模型的编码器和解码器对翻译性能的影响。在大规模的WMT20 En-De数据集上的实验结果表明,非对称结构(如更大的编码器和更小的解码器)可以实现与NAT-Big模型相当的性能,同时保持与NAT-Base模型相当的解码速度。
论文4. 题目:A Sequence-to-Sequence&Set Model for Text-to-Table Generation(作者:Tong Li,Zhihao Wang,Liangying Shao,Xuling Zheng,Xiaoli Wang,Jinsong Su;收录情况:findings, long paper)。本文由中心2020级硕士生李彤同学、2020级博士生王志豪同学、郑旭玲老师、苏劲松老师等合作完成。
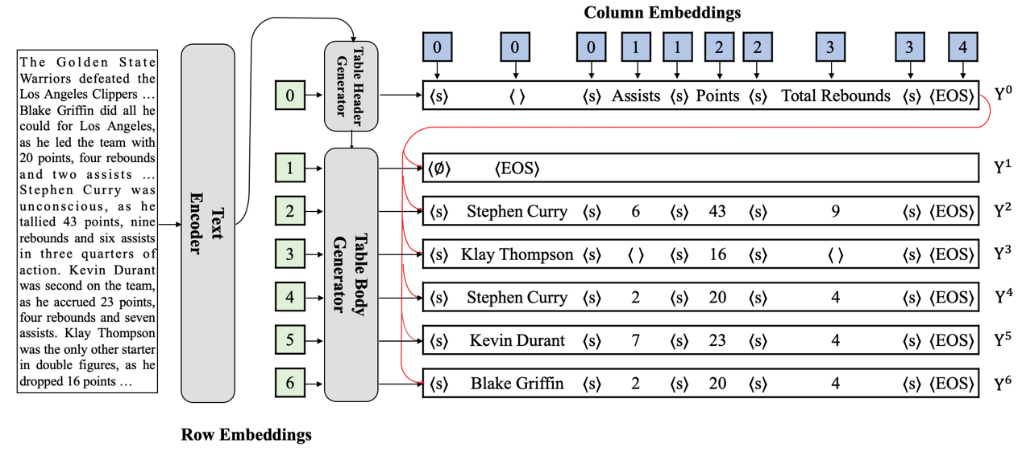
文本到表格的生成任务是一项信息抽取领域的新兴任务。主流模型将这一任务形式化为序列到序列的生成任务,在训练阶段自上而下地拼接所有行,将每个表格表示为一个文本序列。然而,它有两个严重的缺陷:预定义的行顺序在训练过程中引入顺序偏置;长文本序列导致更加严重的错误传播。该文章提出了一个新颖的序列到集合的生成模型。具体来说,首先设计了一个表头生成器,以序列生成的方式输出一个表头,然后使用一个序列到集合的生成器来并行地生成一组表体行。同时为了解决训练过程中每个生成的表体行与训练目标的对应关系的问题,文章提出了使用基于二分图匹配的方法。实验结果表明,该文章提出的模型在多个数据集上优于现有模型。
论文5. 题目:BigVideo: A Large-scale Video Subtitle Translation Dataset for Multimodal Machine Translation(作者:Liyan Kang, Luyang Huang, Ningxin Peng, Peihao Zhu, Zewei Sun, Shanbo Cheng, Mingxuan Wang, Degen Huang and Jinsong Su;收录情况:findings, long paper)。本文由中心2021级硕士生康立言同学、苏劲松老师和字节跳动火山翻译黄路扬研究员、王明轩研究员等合作完成。

该研究聚焦于多模态机器翻译研究。近年来的研究指出,现有的多模态翻译数据集(例如Multi30K)存在着规模小,文本简单的缺陷,限制了多模态翻译的研究。针对上述问题,该研究基于西瓜,Youtube视频平台,收集建立一个视频-字幕的翻译数据集。数据集包含超过450M的双语字幕和150K的对应视频片段。为了进一步评估视频模态在文本翻译中发挥的作用,将测试集通过人工评估划分为两个子集,一个子集的字幕需要观看视频才能正确进行翻译和消除歧义,另一个子集中的字幕通过文本内容便可直接翻译。进一步地,还在含有歧义字幕的子集中进行了歧义词标注,通过这些标注词的翻译准确度来衡量视频模态是否得到了好的利用。文章还提出一个基于对比学习的视频-文本统一编码框架,来构建不同模态信息之间的联系。多方面的实验证明了该文章提出的数据集具有大规模高质量的优点,且具有一定难度,同时也证明了提出的框架有效地建立了视频和文本之间的联系。
论文6. 题目:RC3: Regularized Contrastive Cross-lingual Cross-modal Pre-training(作者:Chulun Zhou, Yunlong Liang, Fandong Meng, Jinan Xu, Jinsong Su and Jie Zhou;收录情况:findings, long paper)。本文由中心2022届毕业生周楚伦同学、苏劲松老师和腾讯微信翻译团队、北京交通大学自然语言处理组合作完成。
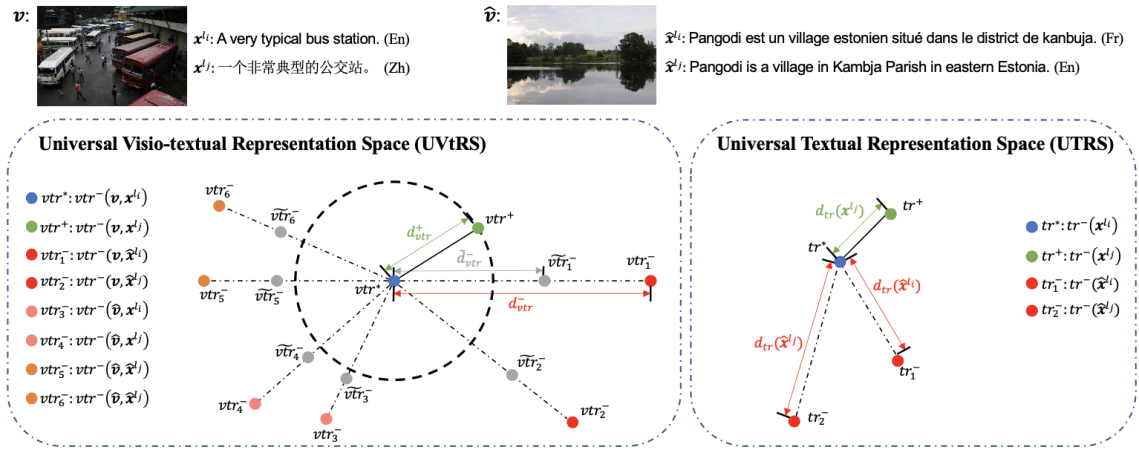
该研究聚焦于视觉-文本预训练研究。已有的视觉-文本预训练工作利用大量图片文本对使模型在预训练的过程中初步具备建模图像和文本信息的能力,从而令其在一系列下游多模态任务上取得良好的表现。上述做法需要利用大量图文严格对齐的多语言数据,当前主要做法是将图片和其对应的英语描述通过翻译引擎生成多个语言上的伪平行语料。然而,获取高质量的图文严格对齐的多语言视觉-文本对数据的成本较高,且伪平行语料质量不易保证。此外,当前视觉-文本预训练方法需要利用外部检测器获取的图像ROI特征,过程耗时且输入形式单一,限制了模型预训练和下游任务灵活性。针对以上两个问题,文章提出了旨在有效利用更广泛存在且更易于收集的大量弱对齐的视觉-文本数据的预训练框架,并提出了regularized visio-textual contrastive learning训练目标。同时,文章在预训练过程中融合ROI-based和Pixel-based的两种图片输入形式,从而令模型在下游不同的多模态任务上具有更好的适应性。多方面的实验证明了该文章提出的视觉-文本预训练方法在涵盖了多个语言的多种视觉文本任务上的有效性。






