近日,我中心语言数据知识计算课题组有4篇论文分别被权威期刊和会议AIJ,JAIR,IPM和IJCAI录用。录用论文相关信息如下:
论文1. 题目: Search-Engine-augmented Dialogue Response Generation with Cheaply Supervised Query Production (作者: Ante Wang+, Linfeng Song+, Qi Liu, Haitao Mi, Longyue Wang, Zhaopeng Tu, Jinsong Su*, Dong Yu; 发表期刊: Artificial Intelligence)。本文由我中心2022级博士生王安特,腾讯西雅图实验室研究员宋林峰博士,中心苏劲松老师等人合作完成。
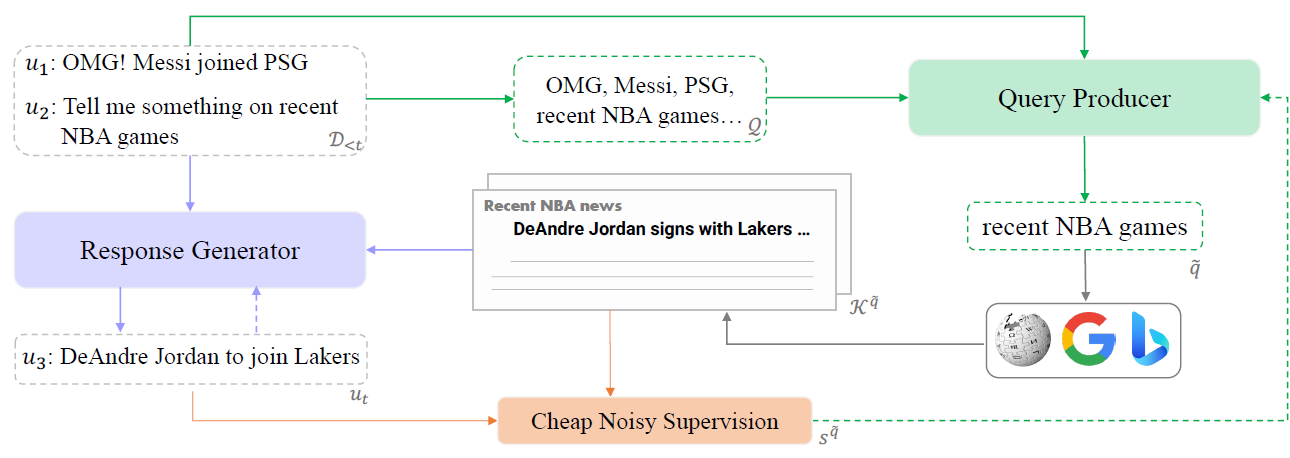
本研究关注基于搜索引擎知识辅助的对话系统,针对其中关键的查询生成模型,提出一种无需人工标注数据的弱监督训练方法。该方法以关键词检索结果与对话回复的相似度作为弱监督信号,指导查询生成模型的训练。本研究充分探究了该方法在不同查询生成模型与对话回复生成模型上的效果,Wizard-of-Wikipedia数据集上实验证明:提出的查询生成模型相比传统无监督关键词抽取模型具有更高的目标文档召回率,此外,生成的对话回复质量也更高。
论文2. 题目: FactGen: Faithful Text Generation by Factuality-aware Pre-training and Contrastive Ranking Fine-tuning (作者: Zhibin Lan, Wei Li, Jinsong Su*, Xinyan Xiao, Jiachen Liu, Wenhao Wu, Yajuan Lyu; 发表期刊: Journal of Artificial Intelligence Research)。本文由我中心2022级硕士生蓝志彬,百度研究员李伟博士,首席研究员肖欣延博士,中心苏劲松老师等人合作完成。
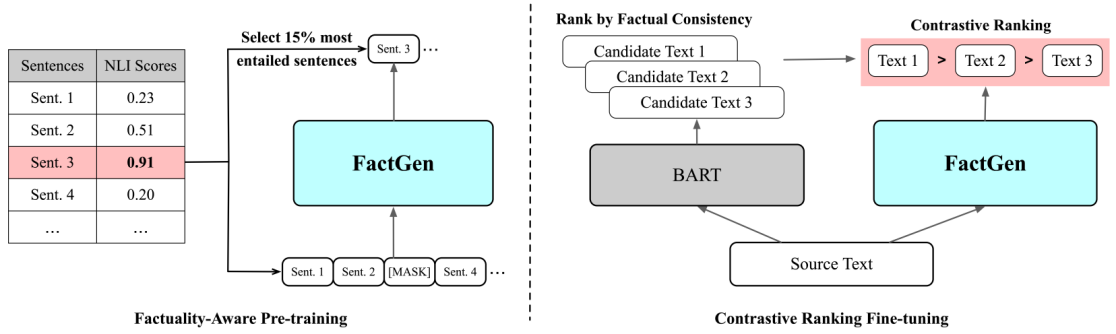
本研究聚焦于基于预训练的文本生成模型的事实一致性研究。事实一致性问题指的是模型生成的文本与原文内容或客观事实相违背,这限制了文本生成模型在实际场景中的应用。针对该问题,本研究提出了一种事实感知的预训练微调框架。具体而言,在预训练阶段,我们利用自然语言推理模型来辅助构建更加事实一致的训练实例;在微调阶段,我们构建多个候选文本让模型排序,然后使用对比排序损失函数优化模型,使得模型对于更符合事实一致的文本具有更高的生成概率。摘要,对话,表格生成文本这三个任务上的实验结果和深入分析证明了本研究方法的有效性和通用性。
论文3. 题目: From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey (作者: Binbin Xie+, Jia Song+, Liangying Shao+, Suhang Wu, Xiangpeng Wei, Baosong Yang, Huan Lin, Jun Xie, Jinsong Su*; 发表期刊: Information Processing & Management)。本文由我中心2021级硕士生谢彬彬, 2022级硕士生邵良颖,宋佳,阿里巴巴达摩院研究员魏相鹏博士,杨宝嵩博士,中心苏劲松老师等人合作完成。
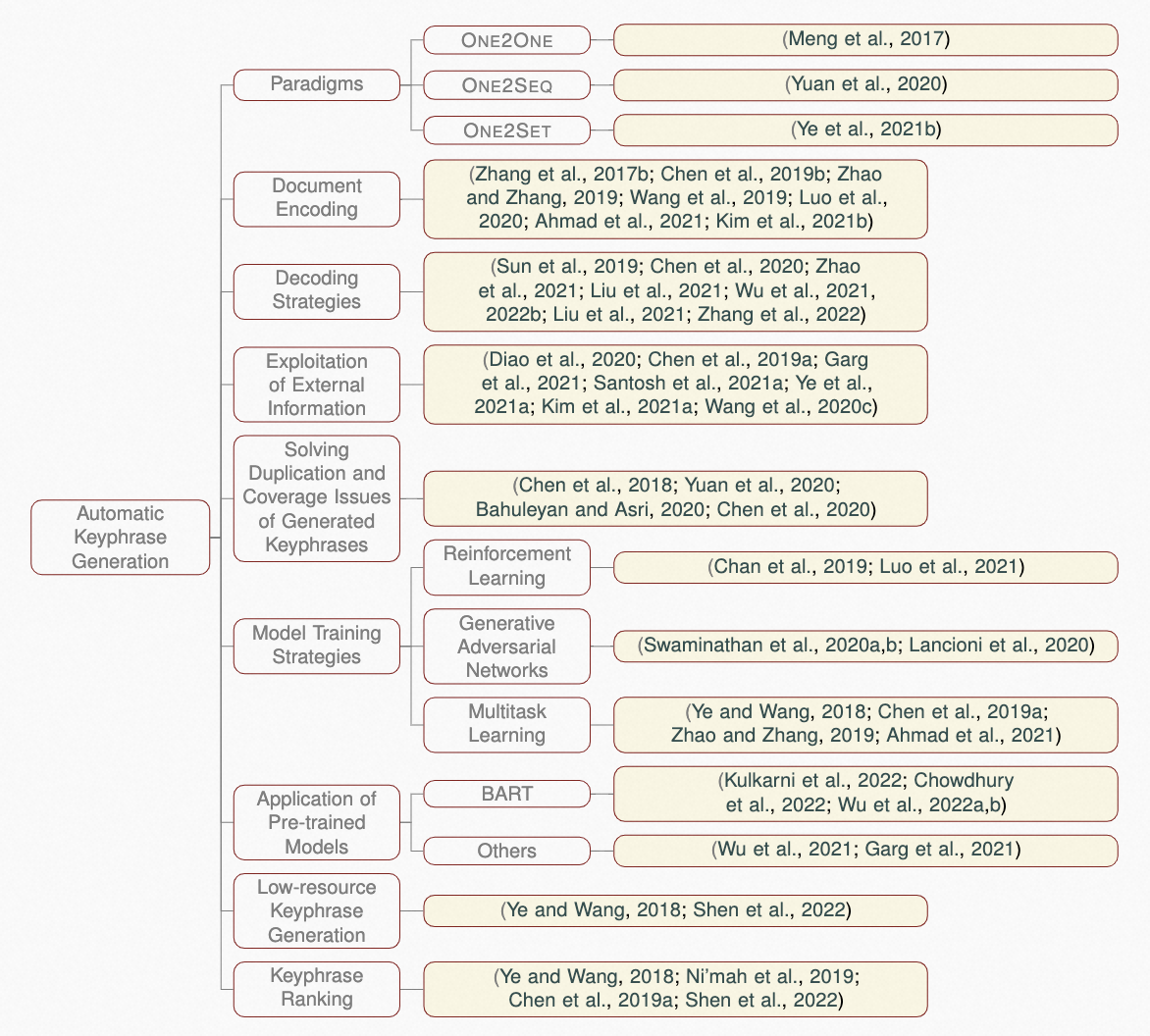
本研究全面综述关键短语预测的研究进展,涵盖该领域160多篇论文。首先,我们对关键短语预测任务的经典模型进行分类;然后,对它们分别进行综述介绍,阐述模型主要思想;再紧接着,我们通过实验对比不同代表性模型,包含短语抽取模型,短语生成模型,和基于预训练模型的短语生成模型,分析它们各自的优缺点;最后,我们仔细讨论该任务的未来发展方向,以启发后续研究。
论文4. 题目: Exploring Effective Inter-encoder Semantic Interaction for Document-Level Relation Extraction (作者: Liang Zhang+, Zijun Min+, Jinsong Su*, Pei YU, Ante Wang, Yidong Chen*; 发表会议: IJCAI)。本文由我中心2020级硕士生张亮与2019级本科生闵子君,中心苏劲松老师,智能系陈毅东副教授等人合作完成。

本研究聚焦于使用图神经网络来改善文档级关系抽取模型的关系推理能力。具体而言,我们提出了一个文档图编码器,其不仅能够同时捕获文档图节点的全局和局部上下文信息,而且能够捕获文档中的非实体线索信息来改善模型的推理能力。同时,我们引入了两个辅助任务:图节点重构任务和对抗蒸馏任务,他们能够有效地促进文档编码器和图编码器之间的语义交互。最后,我们在四个常用的文档级关系抽取数据集上验证了我们方法的有效性。






