近日,厦门大学信息学院苏劲松教授课题组,北京交通大学自然语言处理课题组和腾讯微信模式识别中心在国际计算机学术期刊IEEE Transactions on Pattern Analysis and Machine Intelligence上合作发表了题为“A Multi-task Multi-stage Transitional Training Framework for Neural Chat Translation”的最新研究成果。

随着全球化的发展,来自不同国家的人产生了大量针对跨语言对话进行翻译的需求。神经对话翻译旨在利用神经网络模型将属于一名对话者所讲的内容翻译为另一名对话者所属的语言。与传统神经机器翻译模型不同,神经对话翻译模型不仅要建模当前翻译的对话者表达,而且还要充分利用对应的对话历史上下文信息。该任务的传统做法是采用预训练—微调的两阶段训练方式,即在大规模平行句对上进行预训练,然后在数量较少的双语平行对话数据上进行微调。然而这种方法存在以下难题:1)微调阶段所用的双语对话数据量极小且获取成本较高;2)两个阶段对于模型的训练目标存在不一致,第一阶段只训练模型句子级翻译能力,第二阶段要直接使模型能够建模对话历史上下文,进行感知上下文的对话翻译;3)现有模型产生的对话译文全文连贯性较差,不符合对话者本身的表达特点。
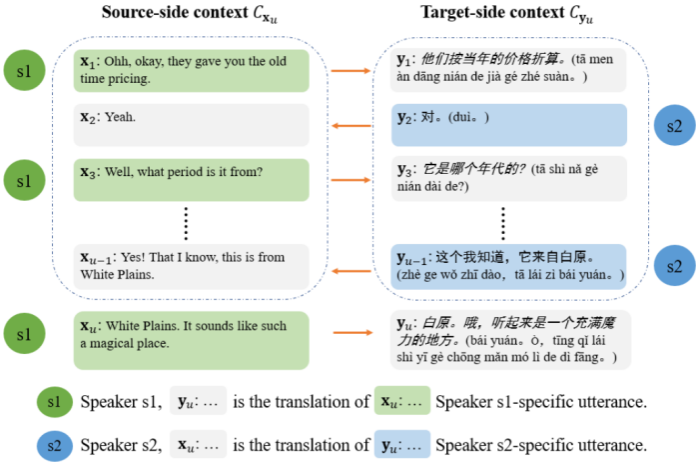
图1. 神经对话翻译
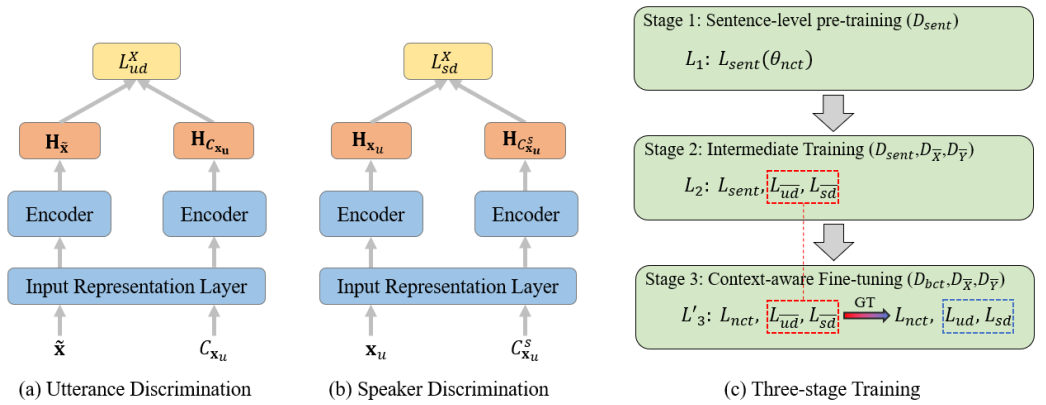
图2. 渐进式多任务多阶段训练框架
针对上述存在的问题,本研究提出了一种渐进式多任务多阶段训练框架。其中,针对用于微调的双语对话数据数量少且获取成本高的问题,提出利用额外的单语对话数据来增强神经对话翻译模型能力;针对模型在不同阶段的训练目标不一致的问题,提出在不同阶段的训练目标之间进行渐进式过渡训练,使得模型更好地适应不同阶段的训练目标,针对现有模型产生的对话译文存在全文连贯性较差,不符合对话者本身的表达特点,进一步从对话具有的两种基本特性(对话连贯性、对话者表达特点)设计了两个辅助任务,以此来更好地利用单语和双语对话语料。
研究团队在英德和英中两个语言对的四个翻译方向上进行了实验,并与本任务上其它具有上下文感知能力的翻译模型进行了充分对比。相关实验结果和分析验证了本工作提出训练框架的有效性。
该项工作由原信息学院硕士生周楚伦(信息学院2022届硕士,现腾讯微信研究员)、北京交通大学博士生梁云龙完成主要研究工作,为文章的共同第一作者,信息学院苏劲松教授为通讯作者。该工作也是周楚伦同学继ACL2020、ACL2021、EMNLP2021、ACL2022之后第5个关于机器翻译、文本生成的研究工作。此外,腾讯微信模式识别中心孟凡东研究员、总监周杰博士、北京交通大学徐金安教授、厦门大学王鸿吉副教授、哈尔滨工业大学(深圳)张民教授也对本研究工作给予大力帮助和支持。
该工作得到了国家自然科学基金 (62036004、61672440)、福建省杰出青年基金(2020J06001) 等相关项目的资助。
论文链接:https://ieeexplore.ieee.org/document/10003654






