近日,自然语言处理国际会议EMNLP 2022公布录用结果。我中心语言数据知识计算课题组有7篇论文被录用。EMNLP会议由国际计算语言学协会举办,是CCF-B,THU-A类会议。此次被录用的论文的相关信息如下:
论文1. 题目:Towards Robust k-Nearest-Neighbor Machine Translation(作者:Hui Jiang, Ziyao Lu, Fandong Meng, Chulun Zhou, Jie Zhou, Degen Huang and Jinsong Su;收录情况:main conference, long paper)。本文由我中心2020级硕士生蒋辉同学、苏劲松老师、腾讯微信模式识别中心陆紫耀研究员、孟凡东研究员等合作完成。
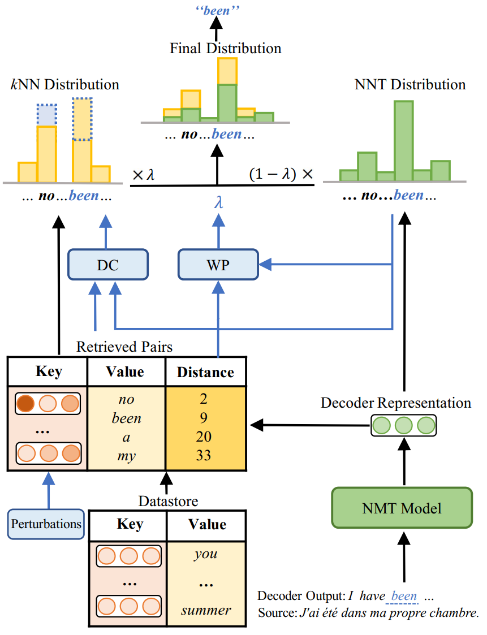
本文指出在基于检索的k近邻机器翻译模型中,检索到的含噪结果会显著破坏模型的性能。因此,我们在计算k近邻分布和动态权重时,考虑了翻译模型本身的置信度信息,来增强模型的鲁棒性。此外,我们也加入两种扰动来进行鲁棒训练。在多个数据集的实验结果表明我们的方法有更好的性能和鲁棒性。
论文2. 题目:Towards Better Document-level Relation Extraction via Iterative Inference;作者:Liang Zhang, Jinsong Su, Yidong Chen, Zhongjian Miao, Zijun Min, Qingguo Hu and Xiaodong shi;收录情况:main conference, long paper)。本文由我中心2020级硕士生张亮同学、苏劲松老师、陈毅东老师等合作完成。

本文指出文档级关系抽取中实体之间的关系存在预测难易不同的问题,比较难预测的关系往往可以借助容易预测的关系通过关系推理预测出来。为此,我们给标准模型引入一个推理模块来有效建模实体对之间相关性。增强后的模型可以通过迭代解码由易到难地抽取文档中的实体关系。此外,我们引入了对比学习来有效地训练我们的推理模块。多个数据集的实验结果证明了我们模型的有效性。
论文3. 题目WR-ONE2SET: Towards Well-Calibrated Keyphrase Generation:作者:Binbin Xie, Xiangpeng Wei, Baosong Yang, Huan Lin, Jun Xie, Xiaoli Wang, Min Zhang and Jinsong Su;收录情况:main conference, long paper)。本文由我中心2021级硕士生谢彬彬同学、苏劲松老师、阿里巴巴达摩院魏相鹏研究员、杨宝嵩研究员等合作完成。
本文指出标准关键短语集合生成模型存在严重的校准错误,其主要表现为对于空值的过估计问题。本文分析了该问题存在的两大原因:空值数量过多和训练阶段标签匹配不固定。为了解决上述问题,我们提出利用实例级别的加权损失策略和标签重匹配方法。多个数据集的实验结果证明了本文提出的方法的有效性和通用性。
论文4. 题目:Getting the Most out of Simile Recognition(作者:Xiaoyue Wang, Linfeng Song, Xin Liu, Chulun Zhou, Hualin Zeng and Jinsong Su;收录情况:findings, long paper)。本文由我中心2021级博士生王笑月同学、苏劲松老师、腾讯西雅图人工智能实验室宋林峰研究员等合作完成。
本文针对现有明喻识别与抽取模型没有充分挖掘明喻任务特点的缺陷,分别从编码端和解码端丰富输入特征信息来提升模型性能。一方面,我们基于词性,句法,外部知识构建异构图丰富编码端信息;另一方面,我们使用了先抽取本体后喻体,先抽取喻体后本体,并行抽取这三种解码方式丰富解码端信息;最后,标准数据集的实验结果证明本文提出方法的有效性。
论文5. 题目:Adaptive Token-level Cross-lingual Feature Mixing for Multilingual Neural Machine Translation(作者:Junpeng Liu, Kaiyu Huang, Jiuyi Li, Huan Liu, Jinsong Su and Degen Huang;收录情况:main conference, long paper)。本文由大连理工黄德根老师课题组和我中心苏劲松老师等合作完成。
本文针对当前多语言机器翻译模型对语言特有知识和相近语言间共享知识建模能力不足的问题,从子词表征层面对每种语言的特征进行提取和构建。首先,将每个子词表征映射到不同的子空间来对不同的特征进行建模;之后对不同子空间的特征进行融合得到新表征并利用门机制计算各种特征的融合比例。通过控制不同语言的特征融合比例动态调整语言间的知识共享程度,从而在促进语言之间知识迁移的同时降低相互干扰。实验结果证明了本文方法的有效性。
论文6. 题目:Sentiment-Aware Word and Sentence Level Pre-training for Sentiment Analysis(作者:Shuai Fan, Chen Lin, Haonan Li, Zhenghao Lin, Jinsong Su, Hang Zhang, Yeyun Gong, JIan Guo and Nan Duan;收录情况:main conference, long paper)。本文由厦门大学林琛老师课题组、微软亚洲研究院和我中心苏劲松老师等合作完成。
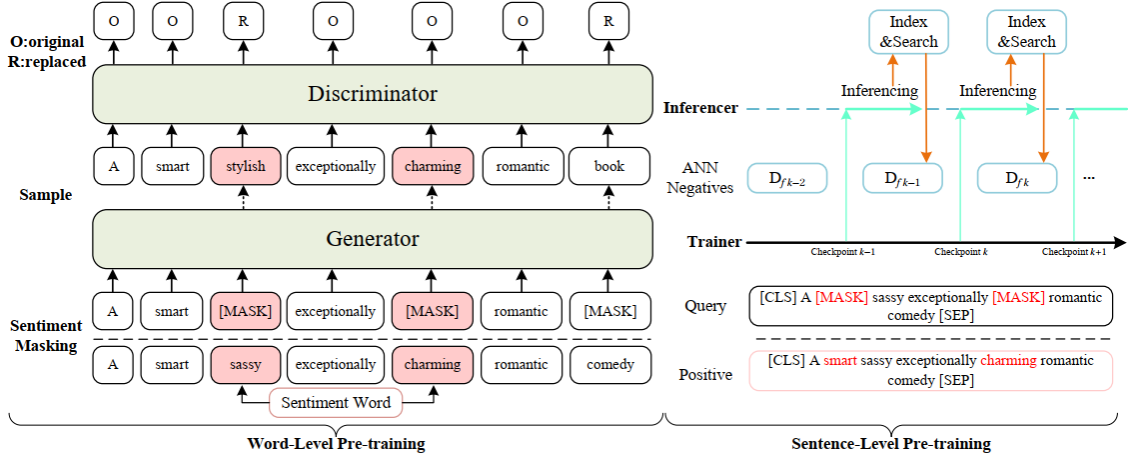
本文针对现有预训练语言模型未对情感分类问题优化的缺陷,提出了SentiWSP模型,分别从词级别和句子级别改进传统的预训练模型。在该模型中,我们采用了一个生成器判别器框架,在词级别预训练任务中探测被替换的词语,在句子级别使用对比学习进一步强化判别器,采用相似句子作为负例,丰富句子级别情感信息编码。在多个开放数据集上的实验验证了该方法的有效性。
论文7. 题目:CLLE: A Benchmark for Continual Language Learning Evaluation in Multilingual Machine Translation(作者:Han Zhang, Sheng Zhang, Yang Xiang, Bin Liang, Jinsong Su, Zhongjian Miao, Hui Wang and Ruifeng Xu;收录情况:findings, long paper)。本文由哈工大徐睿峰老师课题组和我中心苏劲松老师、缪忠剑同学等合作完成。
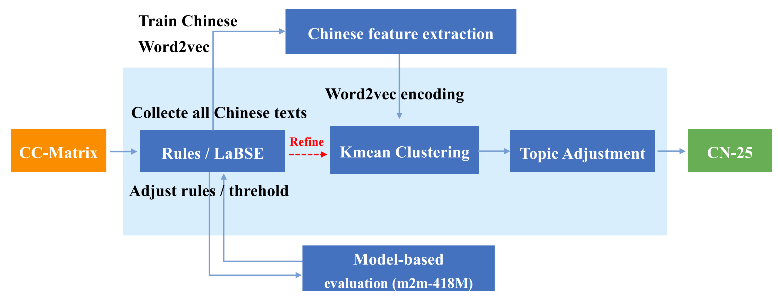
本文提出一种语言可持续学习的机器翻译评估基准CLLE,定义了两种语言可持续学习的机器翻译任务—近距离语言持续学习(CLCL)与语系持续学习(LFCL)。我们使用基于多语言检索模型的方法对CC-Matrix数据集进行过滤,通过主题对齐得到了以中文和英文为核心的覆盖25种语言的多语翻译数据集CN-25和EN-25;并提出了基于元学习与限制优化的语种持续学习框架COMETA,在COMETA框架中元模型可以预测翻译模型的参数重要性权重,以此保护旧语言在持续学习时不被遗忘。






