近日,自然语言处理国际会议ACL 2022公布录用结果。我中心自然语言处理研究组有2篇论文被录用为主会长文,1篇论文被录用为findings of ACL 2022。ACL会议由计算语言学协会举办,有着严苛的录用标准,被中国计算机学会认定为A类会议。此次被录用的论文的相关信息如下:
论文1. 题目:Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation(作者:Chulun Zhou, Fandong Meng, Jie Zhou, Min Zhang, Hongji Wang, Jinsong Su;收录情况:main conference, long paper)。本文由我中心2019级硕士生周楚伦同学、苏劲松老师、腾讯微信团队合作完成。
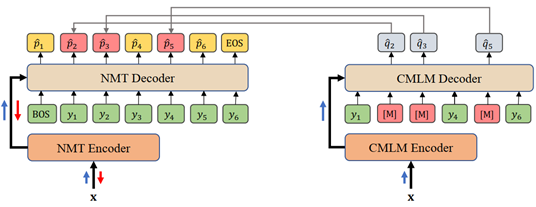
本文为句子级翻译模型提出了基于置信度的融入全局上下文的两阶段训练框架。 在该框架下,翻译模型与一个条件掩码语言模型(CMLM)联合进行训练。具体地,基于翻译模型在给定目标端正确前序词情况下对目标答案预测的置信度,我们将 CMLM 作为教师模型,通过选择性知识蒸馏,为翻译模型在目标端有针对性地融入目标端双向全局上下文信息,从而使翻译预测在每个时刻不仅仅局限于前序词所包含局部历史上下文。实验结果表明本文方法在多个公开数据集上有效提升了模型翻译效果。
论文2. 题目:A Variational Hierarchical Model for Neural Cross-Lingual Summarization(作者:Yunlong Liang, Fandong Meng, Chulun Zhou, Jinan Xu, Yufeng Chen, Jinsong Su and Jie Zhou;收录情况:main conference, long paper)。本文由北京交通大学团队、腾讯微信团队、我中心2019级硕士生周楚伦同学(共同一作)和苏劲松老师共同完成。
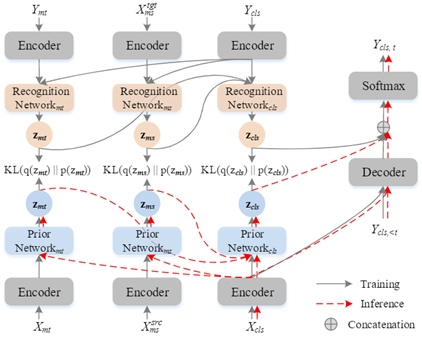
本文提出了一种基于变分自编码器的层次化神经跨语言摘要模型,跨语言摘要任务本质上可以看作是机器翻译任务和单语摘要任务的结合,二者存在层次化的关系。因此,基于变分自编码器结构,我们在局部和全局层次分别设计了相应的隐变量。在局部层次,我们设计了两个隐变量,分别对应翻译任务和摘要任务;在全局层次,我们设计了另一个基于两个局部隐变量的隐变量。在中英和英中两个方向上,我们的模型相比于现有方法取得了提升,并且在few-shot设定下取得了更加明显的效果。
论文3. 题目:Type-driven Multi-Turn Corrections for Grammatical Error Correction(作者:Shaopeng Lai, Qingyu Zhou, Jiali Zeng, Zhongli Li, Chao Li, Yunbo Cao, Jinsong Su;收录情况:findings, long paper)。本文由我中心2020级硕士生赖少鹏同学、苏劲松老师、腾讯微信云小微团队合作完成。

本工作针对语法纠错任务的一步到位训练和多轮迭代预测所产生的曝光偏差问题,提出一种多轮纠错训练的训练策略,并在该任务上第一次探索了不同纠错行为之间的相互影响。通过量化实验发现:先完成“插入”和“替换”类型的纠错显著有利于其他语法错误的纠正。进一步地,利用发现的现象结合训练策略提出了更精细的训练方法,取得了更好的效果。集成了该方法的模型所取得的纠错性能目前在BEA-2019语法纠错榜上排名第一。






