近日,自然语言处理国际会议ACL-2021公布录用结果,我中心自然语言处理研究组有5篇论文入选。ACL是自然语言处理的顶级会议,被中国计算机学会认定为A类会议。此次被录用的论文的相关信息如下:
1、Towards User-Driven Neural Machine Translation. (main conference, long paper)

本文由我中心2019级硕士研究生林欢,达摩院姚亮博士,杨宝嵩博士,刘大一恒博士,张海波博士,骆卫华博士,大连理工黄德根教授和苏劲松教授(通讯作者)等合作完成。本文针对神经机器翻译系统在实际应用场景中面临的用户特征建模困难以及缺少相应标注数据问题,提出了用户驱动的NMT架构,通过cache机制和对比学习实现了零资源条件下的用户特征建模,从而进行个性化翻译。此外,本文建立了首个参考用户特征标注的中-英翻译数据集,为后续研究提供支持。
2、Bridging Subword Gaps in Pretrain-Finetune Paradigm for Language Generation.(main conference, long paper)

本文由我中心2019级硕士研究生刘鑫,达摩院杨宝嵩博士,刘大一恒博士,张海波博士,骆卫华博士,苏州大学张民教授,张海英副教授和苏劲松教授(通讯作者)等合作完成。本文针对在预训练-微调流程下存在的上下游任务期望的词粒度不匹配问题,提出了词嵌入转换模块,通过在上游数据集中的无监督训练,该模块能在给定任意下游词表情况下完成词嵌入的转换生成,从而增强语言生成模型在下游的表达能力。在多个模型、数据集下的实验结果都验证了模块的有效性。
3、Exploring Dynamic Selection of Branch Expansion Orders for Code Generation.(main conference, long paper)
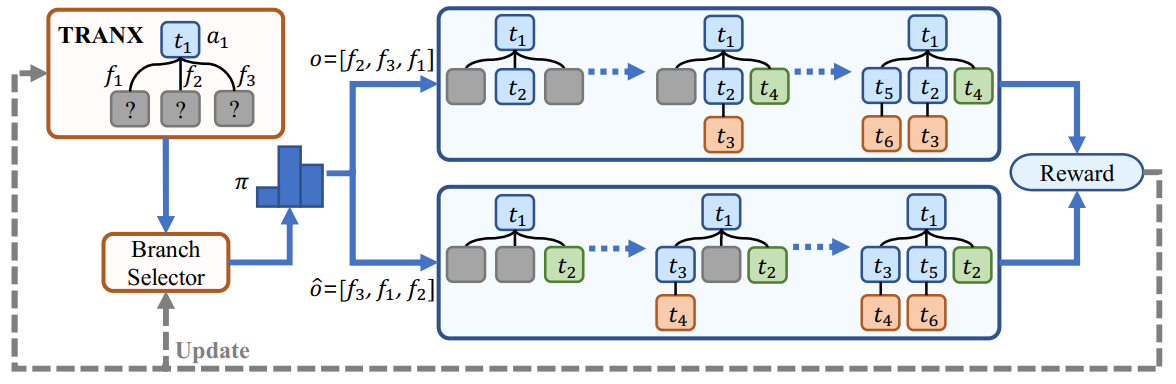
本文由我中心2020级硕士生蒋辉,2019级硕士生周楚伦,腾讯微信孟凡东博士,爱丁堡大学张飚博士,腾讯微信周杰博士,大连理工黄德根教授, 吴清强教授和苏劲松教授(通讯作者)等合作完成。本文针对在抽象语法树生成过程中,都是通过先序遍历生成节点的问题,提出使用一个决策网络来动态选择分支的顺序,采用强化学习的方法来同时训练模型和决策网络,并且我们设计了新的奖励函数,使用不同分支顺序生成的Loss的差来表示当前分支选择的好坏。在多个公开数据集上证明了模块的有效性。
4、BACO: A Background Knowledge- and Content-based Multi-perspective Framework for Citation Text Generation. (main conference, long paper)
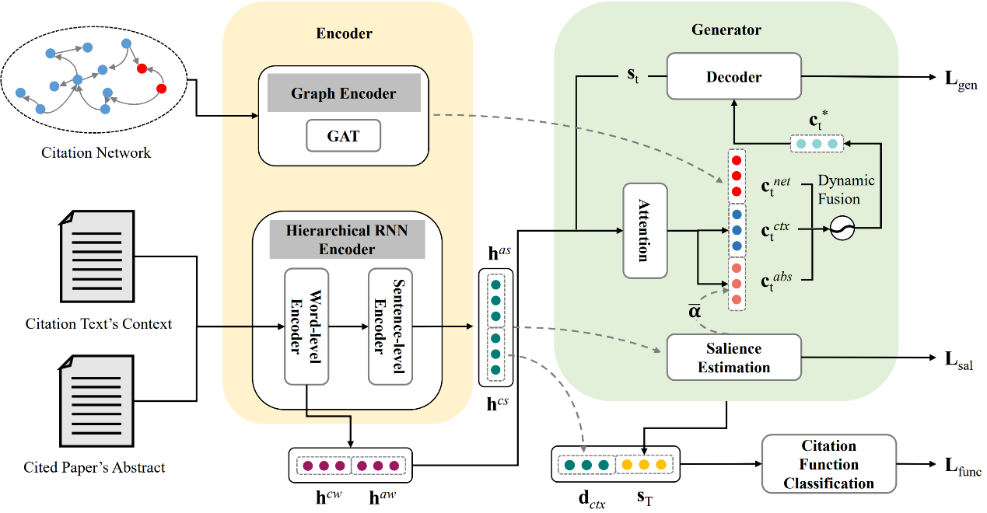
本文由伊利诺伊大学厄巴纳-香槟分校、哈佛大学和苏劲松教授、2018级硕士研究生陆紫耀和2019级硕士研究生王安特共同完成。本文针对引用文本生成任务,提出了一种融合背景知识和深层内容信息的框架来提升模型性能。具体来说,本文使用图注意力网络来抓取基于引用网络的背景知识,同时显性得学习被引文章中的句子重要性和引用功能作为深层内容信息,并将这些信息结合进解码器来提供更丰富的信息以强化模型。
5、Exploiting Chinese Word Segmentation via Pseudo Labels for Practicability. (findings, long paper)

本文由大连理工大学、天津大学和苏劲松教授共同完成。本文针对中文分词模型在应用领域缺少实用性的问题,提出一种半监督学习方法来给无标签数据打上伪标签。通过知识蒸馏的方法,来缓解跨领域的中文分词任务。实验结果表明轻量的学生模型即可有效改进模型的性能。






